
The Signpost tagging initiative
The Signpost has been in continuous weekly publication on the English Wikipedia since its foundation in early 2005 by future (now well-former) Board chairman Michael Snow. And over more than a decade of weekly publication we have accumulated an incredibly lengthy and detailed record about the issues, controversies, successes, and failures of the English Wikipedia community and the movement at large.
The movement has advanced almost incomprehensibly far since then; today the Wikimedia Foundation employs 280+ staffers running the fifth most visited website in the world. And no one's kept better track of the progress than the Signpost has. The contents of the Signpost archive contain the most extensive record available anywhere or to anyone of the things that have mattered and continue to matter to the community, and by browsing the Signpost archives editors can familiarize themselves with any and all of the things that matter in the community, from VisualEditor to semi-protection to hoax-making to editcountitis. Even things that most have forgotten about: for instance, how many remember that recently-retired vice president of engineering and long-time Wikipedian Erik Möller was working on a "Wikidata" concept all the way back in 2005 (we do)? How many of us have ever heard of nofollow (we have)?
Yet for all of its richness the Signpost archives are rarely used. Searching the archives for information on what you want is a pain, and since the results will be returned out of order it is the onus of the person doing the search to figure out what happened in what order. While doing research for a story I am, by way of the effort that I must make in reconstructing sequences of events through the Signpost archives, reminded of why hardly anyone ever does it. Articles are written and read, then archived and never heard from again; yet there is a rich wealth of information that the community could potentially make use of, a decade's worth of publications informing who we are and where we came from that is just too hard to pick apart to be of any use to anyone.
We at the Signpost have been hard at work over the past few months building up a systematic way to change that.
How can you help?
Though the technical framework is now almost complete, the bulk of the content work remains to be done. Before we can develop our initiative any further we need input from you, our readers, on what these tags actually are. A lot of things have happened over the decade and we don't pretend to know all of them; for this reason we need your help coming up with as comprehensive a list of tags as possible. It's imperative that, before we begin, we have as complete a list as possible of all of the important things that have happened on Wikipedia—and so we are asking for your help defining just what those things are.
Help us out! Head over to our Etherpad and start adding your thoughts to it as much and as soon as you can!
What am I helping build here?
We're not ready yet to reveal the full technical details of the project, which are still in alpha and under constant revision. But you can look at some early results nonetheless by trying some of the following links. Try a few yourself!
— Resident Mario, Signpost associate editor
Reader comments
Content Translation beta is coming to the English Wikipedia
The Wikimedia Foundation's Language Engineering team plans to introduce Content Translation—a tool that makes it easier to translate Wikipedia articles into different languages—as a beta feature on the English Wikipedia.
Content Translation is an article creation tool that allows editors to quickly create an initial version of a new article by translating from an existing Wikipedia page of the same topic in another language. The tool is currently available on 224 Wikipedias as a beta feature, and more than 7,000 articles have been created by more than 1,500 editors since January 2015. For the English Wikipedia, we expect to enable as an opt-in beta feature for logged-in users in early July, after its initial Wikimedia testing in July 2014 and beta deployment to multiple Wikipedias in January 2015.
Content Translation saves translators' time by automating common tasks: it adapts formatting, images, links, categories and references, and it automatically adds an interlanguage link. The translated articles created are otherwise just like any other; the tool simply helps create quality content by allowing editors to focus on translating and expanding articles instead of being consumed with the lengthy manual translation process.
Once the tool is activated on the English Wikipedia, you will be enable to the Content Translation by going to your preferences, you can start a translation in the following ways:
- Your contributions page will show a menu on ways to start new contributions, including translations. You can access these options by hovering over the link to the Contributions page.
- Highlight missing interlanguage links. When reading an article, links to some languages for which the article is missing will be highlighted in the interlanguage link area. In this list only a few languages are displayed, which we expect to be relevant for you. This is a quick way to identify the pages that can be translated for the English Wikipedia.
- Visiting Special:ContentTranslation directly. See, for example, Simple.
These features will be visible only to the users who enable Content Translation. After doing this, you can start translating by following these steps:
- Open the tool by going to Special:ContentTranslation or to your contributions page.
- Click on the button to create a new translation.
- In the displayed dialog select the language of the original article and the article name, and the language you would like to translate to. Also add the title of the new article (or the original title will be inserted) and click on to begin. Your language preferences will be remembered for the next time.
- You will see a screen consisting of three columns. The left column contains the text of the source language and the middle column is for the translated text. Using the right column you can perform several actions such as insert source text, remove the inserted text source text, add or remove links etc.
- After you translate the article, you can publish it directly as a new page on the English Wikipedia by using the publish button that appears. In case the article gets created by another user while you were translating, you will see an option to save the newly published translation under your user namespace.
Users do not need to translate the entire article in one session. You can save the translation as a draft within Content Translation and publish it on-wiki when you are satisfied with the results.
Machine translation
Content Translation supports machine translation for a limited set of languages through Apertium, an open-source system. Machine translation is always available for use within Content Translation for any language supported through Apertium and for which we do not encounter any technical blockers. However, it is the user who makes the final choice whether they would like to use machine translation; it is a configurable option that users can choose to deactivate. With an ongoing survey, we are gathering feedback about the quality of machine translations so that we can work with Apertium to improve the service.
Content Translation is a quickly evolving tool, so we attempt to use all of the feedback we receive to improve the everyday experience of our users. Please send us your suggestions, comments and complaints on the Content Translation talk page or through Phabricator. At any time, the number of published pages and other details can be seen on Special:CXStats, the Content Translation stats page—see, for example, fr:Special:CXStats. This page is visible to all users of the wiki.
With the activation of translations into the English Wikipedia, there is a chance that there may be problems that we are not yet aware of. We will be monitoring the tool for these errors, but please do let us know on the Content Translation talk page or through Phabricator if you spot any problems.
Look for Content Translation in July.
For more information, please see the following pages:
- User Guide
- FAQ
- The general project page: mw:Content_translation
- Recent blog post: "Over 5,000 new articles created with the Content Translation tool"
- The Wikimedia Foundation's Language Engineering team is "responsible for providing standards based internationalization and localization tools support for Wikimedia sites on the Web and mobile platforms." It is composed of six team members working on five different projects, including Content Translation.
- The views expressed in this op-ed are those of the Language Engineering team alone; responses and critical commentary are invited in the comments. Editors wishing to submit their own op-ed should use our opinion desk.
Reader comments
Small impact of the large Google Translation Project on Telugu Wikipedia
During 2009–2011 Google ran the Google Translation Project (GTP), a program utilising paid translators to translate most popular English Wikipedia articles to various Indian language Wikipedias. The program was organized as a part of a bid to extend and improve Google Translate software services in various languages: in a presentation[1] at Wikimania 2010 a company presenter stated that "Google has been working with the Wikimedia Foundation, students, professors, Google volunteers, paid translators, and members of the Wikipedia community to increase Wikipedia content in Arabic, Indic languages, and Swahili"; for more background on the effort see Signpost coverage on Wikimania 2010 and Bengali and Swahili experience.
The Google Translation Project was at first visible only through the generation of "Recent changes" items with comments mentioning the use of a "Google translator toolkit".[2] This toolkit was first made public in June 2009; Google initially experimented with Hindi, but quickly expanded the initiative to Arabic, Tamil, Telugu, Bengali, Kannada and Swahili. Google shared the details through a presentation [1] in Wikimania 2010. In the same event, a critique of GTP[3] was presented by a Tamil Wikipedian representing Ravishankar who could not attend due to visa delays. He identified many of the issues facing the project: first, what was popular amongst English readers rarely matched the same amongst Tamil readers, and moreover the many quality problems of the translations (too many red links, mechanical translation, operational problems such as overwriting of stub articles) were all highlighted. Google tried to address the community recommendations on improving the quality of the content generated by engaging in a dialogue but did not succeed. In response to a query from the author Google informed the closure of the project in June 2011.[4] It also announced the launch of indic web and the availability of Google Translate for several indic languages.[5] As one of the first large-scale human aided machine translation efforts on Wikipedia the project also exposed important philosophical friction within the community as to the nature of volunteerism on the projects, friction that, still unaddressed, would go on to re-emerge in the debate over the role and propriety of bots on the Swedish Wikipedia—the wiki passed the million article milestone in 2013, but with almost half (~454,000) of them being bot-created.
In this review the metrics on contributions and page requests from Wikipedia are used to analyze the impact of the project by focusing, as a case study, on just one of the targeted wikis: the Telugu Wikipedia. The entire data and code is also being made available[6] for other communities to validate and apply the analysis to their Wikipedias.
Impact

As of April 2015 the 61,000 articles of the Telugu Wikipedia make it the third largest Indian language Wikipedia, behind Hindi and Tamil.[7] The site has 54 active editors (editors making more than 5 edits a month), ranking it 53rd among the 247 Wikipedia projects with more than 1,000 articles.[8] The site draws ~2.6 M page requests per month.[9] About one third of the wiki's articles describe villages within Telugu speaking states of India, most initially created via bot scripts.
Google provided very little information about the Google Translation Project directly, so the details of its contributions and impact on the Telugu Wikipedia were gathered by scanning for an automatically inserted "http://translate.google.com/toolkit" to the toolkit in revision comments.[10] From this it can be gathered that the Telugu Wikipedia branch of the project ran for 2 years, involving 65 translators and 1989 pages amounting to approximately 7.5 million words.[11] Total cost was estimated to be ~750,000 USD.[12] The project increased the article count by 4.6%, but given the large size of the articles that were translated the project size, a proxy for word count increased by 200%.
Wikipedia edits
Did the work done as part of the Google Translation Project have a long-term impact on editing within the Telugu Wikipedia, positive or negative?
.png)
The graph above charts the yearly change in the number of Wikipedians (active and inactive accounts having made at least one edit) and the growth in project size (measured in millions of words) against the translation project's timetable, demarcated in red. The project came off of a peak in 2007–2008 sourced from a large influx of accounts and edits made following the publication of few features on the Wikipedia in a Sunday edition of Eenadu a major Telugu newspaper during 2006 and 2007 [13] This growth was unrelated to the translation project and lay outside of the time period being considered in June 2009, the month marking the beginning of the translation project. The percentage growth fell already by the time GTP commenced. The percentage growth in the number of Wikipedians declined during the project period and continued to do so after its conclusion, indicating that the GTP had little to no impact on project participation levels. The percentage growth in content, on the other hand, jumped up from about 44% as of June 2009 to 86% and 91% year-to-year in June 2010 and 2011, respectively.
Did this rapid growth stimulate further development in the year afterwards? No. While it is true that the Google Translation Project led to the doubling of the projects' content while it was active, at the project's conclusion the project's growth returned to the same approximately 1 million words per year in growth generated by the core volunteer community before the project's involvement. The absolute figures are shown below:
style="margin: auto;"| Month | Number of accounts with edits | Accounts Growth year-on-year | Project size (millions of words) | Project size Growth year-on-year |
|---|---|---|---|---|
| 2012/06 | 506 | + 78 | 13.8 | + 1.0 |
| 2011/06 | 428 | + 80 | 12.8 | + 6.1 |
| 2010/06 | 348 | + 67 | 6.7 | + 3.1 |
| 2009/06 | 281 | + 57 | 3.6 | + 1.1 |
| 2008/06 | 224 | + 121 | 2.5 | + 1.2 |
| 2007/06 | 103 | — | 1.3 | — |
Even considering the relative sizes of the amount of articles generated and the small size of the core editing community, engagement between volunteers and the articles generated by the GTP remains threadbare: as of May 2015 just 9 out of the 1989 articles created by the project (~0.45% of the total) have received substantial improvements from community volunteers.
Page requests
Google's hypothesis behind launch of the translation project was the idea that more content (meaning more words) naturally leads to more Google searches and there by more page requests. Is this true?
.png)
Above I chart page requests for the entire Telugu Wikipedia for the period June 2009 – June 2012, both raw (in black) and smoothed (in blue). Again, red demarcates the GTP's time period. Page requests reached an all time peak of 4.5M in February 2010 but declined rapidly afterwards, but growth appears to have returned to base levels even before the conclusion of the project. A negative effect on page requests cannot be ascribed to the project—but neither can a positive one. Instead the data simply backs up what Ravishankar had pointed out all the way back in 2010: what was popular amongst English-language readers rarely mattered to their Tamil equivalents, and despite the size and expense of the translation project the sum total of articles generated by the GTP account for just 6% of total page requests (as of March 2014). The same information, put another way: the Telugu Wikipedia features an article assessed as reasonable quality without a formal review process by a senior wikipedian on the front page every week starting June 2007; These volunteer-developed articles equivalent to B-class on English Wikipedia featured there receive, on average, four times the page requests of GTP pages (also as of March 2014) as detailed in the following section.
(Un)popularity of GTP pages
To understand the popularity, non-mobile page request data for GTP and non-GTP featured article pages (This excludes 6 improved GTP pages from featured article pages till Dec 2013) are compared for the month of March 2014. The entire wiki received 1.9M non-mobile page requests. The 1989 GTP pages received a total of 107,424 page requests, amounting to 5.7% of the total. By contrast 328 non-GTP pages featured (till Dec 2013) received a total of 66,805 page requests, amounting to 3.5% of the total. Looking from per page perspective, volunteer-contributed featured articles with 204 page requests per page had about four times the popularity of GTP pages with 54 page requests per page.
The popularity of these pages can also be compared with the village article stubs created during a bot run in 2008, which remained largely unimproved. About 29,820 such pages received 175,640 page requests (based on a sample of 1000 pages receiving 5546 requests and using the one-sample t-test's upper bound of 5.89 for 95% confidence interval). This amounts to 9.2% of page requests. A GTP page with 54 page requests per page is 9 times more popular than a bot-created village stub page with 5.89 page requests per page
The present situation and lessons learned
The improvement generated by the GTP could not be scaled: the Telugu Wikipedia community's growth failed to be stimulated by the GTP and thus did not have the resources to improve the articles generated.
Bringing a semi-automatically translated page like Belgium (illustrated above) up to quality expectation of a typical featured article requires 6–8 hours, appreciation of the quality aspects of pages, easy access to the original English page for clarifications with regard to translation and help to match translated pages with interested Wikipedians. Some community members were upset when some volunteer developed pages were overwritten by GTP and discussed the poor quality of Translated pages several times and also proposed to stop the project during the course of the project. As Google started engaging with Tamil community and assured the Telugu community that community concerns will be addressed after making progress with Tamil first, community did not proceed further. The wait proved futile, as the Tamil community engagement did not succeed and Google announced the project closure in June 2011. As is typical, decision making on small projects is really problematic, as the community is small and the number of people who participate in discussing is about 5–10 and even one objection usually results in rejection of the proposal as assessing a consensus is difficult in such situation.
I have not been able to quantitatively assess the quality felt by a reader when he/she visits a bot created stub or a translated page through surveys. The only WMF survey applicable to Telugu (Global south survey 2014) did not yield any useful results due to the flaws in survey design and implementation. Based on past discussions on Wiki about people playing Wiki as a game by repeatedly clicking 'Random article' link till they hit a decent non bot created article and counting the number of clicks as a measure of quality, I can say that a negative impression is certainly created in the mind of a casual reader in either case, when there is significant percentage of such articles.
Wikipedias grow organically through human editing, with the occasional involvement of bots that seed stubs for topics of interest for the human editors. The GTP project provides an example of an intervention which attempted to grow the content in depth for a smaller number of pages, and it did partially succeed in the sense that the results were significantly more popular than the earlier bot-created village stubs. Unlike those free volunteer-developed bots, however, this project cost hundreds of thousands of dollars of external money and time; given the clear difference between the size and expense of the project, the tiny sliver of the wiki's traffic the pages generate, and the lack of an impact on both page requests and editor numbers, the GTP is a quantifiable failure from Wikipedia editor/reader perspective. The Wikimedia Foundation was not able to see through Google's sole success criteria of number of words added and the potential adverse effects of the project on wikis. It thought the communities would be able to deal with the issue as it is related to content. As the communities themselves are small, they could only make some noises which did not affect the GTP. The WMF was thankful when it received a $2M donation from Google.[14] I hope that this project serves as an eye opener and makes the foundation play a more active role in dealing with external agencies with their own agendas on small wikipedias.
To better manage the growth of Wikipedia, bot projects or translation projects for new pages should carefully consider the ability of the community to support the intervention, by defining the expectation of quality like the scope and depth of coverage and go for a phase wise implementation, with appropriate prioritization. As we have kind of baseline expectation of popularity for either initiative from this study, the proposals should have a specific target above the baseline. Subsequent phase should be taken up with appropriate modifications after assessing the results against the target. This assessment should also include a survey of the readers to ascertain the usefulness of the initiative and impact on the perception of Wikipedia quality. In the case of languages like Telugu with small active communities, these type of initiatives should be taken up only when there is a proper sponsorship for at least one person (full or part time, based on the nature/scope of the initiative) from the foundation or corporate sponsor. Simply trying out such a project because it worked on a large Wikipedia or it seemed to work for a small pilot will not be useful.
Acknowledgements
The author acknowledges the Wikipedia tools makers Domas Mituzas, Henrik, Erik Zachte and Yuvi Panda for the excellent statistics and query support tools. He also acknowledges Ravishankar for the critical review of the Google Translation Project. He thanks Vyzasatya, a Telugu Wikipedian, for his help in reviewing this article. He also thanks the R project team for excellent open source R language and also Coursera R programming course faculty and community for helping the author learn R and use it for this analysis. Thanks are due to The Signpost's editors for their feedback and help in improving the article.
References
- ^ a b Galvej, Michael (2010). "Submissions/Google translation – Wikimania 2010 in Gdańsk". wikimania2010.wikimedia.org. Retrieved 19 June 2015.
- ^ "Google Translate Blog: Translating Wikipedia". googletranslate.blogspot.in. 2010. Retrieved 28 May 2015.
- ^ Ayyakanu, Ravishankar (2010). "A Review on Google Translation project in Tamil Wikipedia - A-Review-on-Google-Translation-project-in-Tamil.pdf" (PDF). pdf.js. Retrieved 28 May 2015.
- ^ A, Ravishankar (2011). "[Wikimediaindia-l] Google's Indic Wikipedia translation project closing down". lists.wikimedia.org. Retrieved 19 June 2015.
- ^ "Official Google Blog: Google Translate welcomes you to the Indic web". googleblog.blogspot.in. 2011. Retrieved 19 June 2015.
- ^ Chavala, Arjuna Rao (2015). "Github repository with data and analysis for data scientists for reproducing/validating the research". github.com. Retrieved 17 June 2015.
- ^ Latest summary statistics of Telugu Wikipedia
- ^ Latest statistics of Telugu Wikipedia
- ^ Latest page requests for Indian languages
- ^ An example of an database query taking advantage of this fact:
- Chavala, Arjuna Rao (2015). "SQL query using Quarry for Pages translated using Google Translate". quarry.wmflabs.org. Retrieved 17 June 2015.
- Chavala, Arjuna Rao (2015). "SQL query using Quarry for Pages translated using Google Translate". quarry.wmflabs.org. Retrieved 17 June 2015.
- ^ Based on an average contribution of 1M words per year by volunteer Wikipedians during 2008/06-2009/06 and 2011/06-2012/06 from the wikipedia statistics table presented
- ^ Assuming 0.10 USD per word of translation, the standard industry rate.
- ^ EENADU (http://eenadu.net), Nov 5,2006, "మన తెలుగు...వెబ్లో బహుబాగు", February 8, 2007 and "వెబ్ లో తెలుగు వెలుగులు", Jun 10, 2007
- ^ "Press releases/Wikimedia Foundation announces $2 million grant from Google – Wikimedia Foundation". wikimediafoundation.org. 2010. Retrieved 22 June 2015.
Reader comments
One eye when begun, two when it's done

Featured articles
Four featured articles were promoted this week.

- 1877 Wimbledon Championship (nominated by Wolbo) The first official men's tennis tournament held on grass later developed into the Grand Slam tournament sports fans know today. Spencer Gore, a rackets player, beat William Marshall in three straight sets. Anyone want to try playing with a racquet from that time?
- HMS Collingwood (1908) (nominated by Sturmvogel 66) Sturmvogel's latest warship article focuses on the early dreadnought battleship Collingwood. The vessel was commissioned in 1910, but by the time the First World War began, Collingwood was already being outclassed by the quickly increasing size and power of the so-called super-dreadnoughts. After the war, the ship was used before being scrapped in 1922, meaning that Collingwood was only 12 years old from completion to scrapping.
- John Wilton (general) (nominated by Ian Rose) Ian writes in his nomination statement that "The 'epitome of the professional army officer', as his biographer David Horner put it, John Wilton was as cool and 'proper' as his clipped moustache and stern visage suggested, but a leader who always seemed to have the welfare of his soldiers at heart." Wilton served as Australia's army and defense chief for several years—both during the Vietnam War, in which the Australian army, navy, and air force were deployed.
- xx (album) (nominated by Dan56) This eponymous album from an English indie pop group was released in 2009 to widespread acclaim—one average of critical reviews pegged xx at an 87 out of 100. It was so popular that when xx's second album was released in 2011, their first was still ranked at 37th on the British chart.
-
 I'm a little teapot, short and stout;
I'm a little teapot, short and stout;
Here is my handle, and here is my spout.
If you tip me over, guards will shout
Because I'm National Treasure No. 61 of South Korea. -
 Jack Johnson is a musician in the folk rock, soft rock, and acoustic rock genres who achieved success with his first album, Brushfire Fairytales.
Jack Johnson is a musician in the folk rock, soft rock, and acoustic rock genres who achieved success with his first album, Brushfire Fairytales.


Featured pictures
Nine featured pictures were promoted this week.


,_2015-05-17.jpg)
- Green lacewing fly (created and nominated by Alvesgaspar) Species of Chrysopa, such as this one, is a type of green lacewing fly which feed on aphids and other pest species.
- Daruma doll (created and nominated by Crisco 1492) Daruma dolls are a Japanese traditional doll based on Zen Buddhism's founder, Bodhidharma. They are considered a sign of good luck. This one is seen as commonly sold: Without pupils, as drawing the pupils in is part of a ritual for planning and completing a task.
- Actin Filaments in a Cultured Cell (created and nominated by Methylated603 (Howard Vindin)) A cultured osteosarcoma (bone cancer) cell fluorescently dyed to reveal the positions of actin, an important structural protein within the cell. Colours show the height of the actin fibre at that point, with 80 nanometer vertical resolution. This work shows a high degree of technical achievement; as one of the voters said, "I used to make pictures like these! Yours is much better than my best."
- Airbus A380 (created by Julian Herzog; nominated by Julian Herzog) An Airbus A380, in the Emirates Airlines livery, photographed in flight. It's a lovely photo, sharp and high resolution.
- Jack Johnson (created by Peterchiapperino; nominated by Crisco 1492) Surfer-musician-actor Jack Johnson also directed and acted in several films, including Thicker Than Water and The September Sessions, besides recording several notable albums, such as Brushfire Fairytales and Sing-A-Longs and Lullabies for the Film Curious George.
- Monument to Alfonso XII of Spain (created by Carlos Delgado; nominated by Crisco 1492) King of Spain from late 1874 to his death in 1885, Alfonso XII came to power at the end of the First Spanish Republic, and is noted for presiding over the restablishment of Spain's economy after a crisis.
- Ruby Loftus Screwing a Breech Ring (created by Laura Knight; nominated by Crisco 1492) Ruby Loftus was one of many women who joined the war effort in Second World War-era Britain by working in factories. This painting, by noted artist Dame Laura Knight, was commissioned by the War Artists' Advisory Committee, and raised Loftus to the position of the British Rosie the Riveter. Despite the name, this image is not pornographic and is perfectly safe for work. A breech ring need not be kept inside one's breeches. Unless you're a prude.
- Salak (created and nominated by Crisco 1492) A sweet, acidic fruit, also called snake fruit due to its scaly skin, salak grows on a type of palm tree native to Java and Sumatra in Indonesia. It looks delicious! How dare Chris tempt us all so?!
- Celadon kettle in the shape of a dragon (created by National Museum of Korea; nominated by Blorgy555) The 61st item to be designated a National Treasure of South Korea, this Goryeo ware kettle in the shape of a dragon, no-one who read the title of the image will be surprised to learn, dates from the 12th century (and is in superb condition). It is made with celadon glaze, and is representative of a type of Korean pottery that reached a zenith of artistry in the 11th and 12th centuries, before being suppressed by the new rulers after a Mongol invasion, for reasons that must have made sense at the time!
-
 Ruby Loftus Screwing a Breech Ring (1943) by Laura Knight.
Ruby Loftus Screwing a Breech Ring (1943) by Laura Knight. -
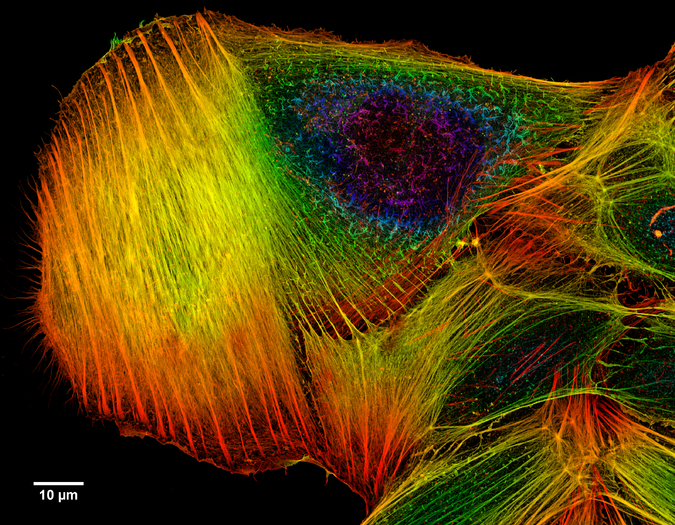 Actin filaments in a cultured bone cancer cell, colour-coded for depth.
Actin filaments in a cultured bone cancer cell, colour-coded for depth.
_(Art._IWM_LD_2850).jpg)

Reader comments
How Wikipedia built governance capability; readability of plastic surgery articles
A monthly overview of recent academic research about Wikipedia and other Wikimedia projects, also published as the Wikimedia Research Newsletter.
How Wikipedia built governance capability, 2001–2009
This paper[1] looks at the topic of Wikipedia governance in the context of online social production, which is contrasted with traditional, contract-bound, hierarchical production models that characterize most organizational settings. Building on the dynamic capabilities theory, the authors introduce a new concept, "collective governance capability", which they define as "the capability of a collective arrangement to steer a production process and an associated interaction system". The authors ask the research question, "How does a collective governance capability to create and maintain value emerge and evolve in online social production?"
.jpg)
- Quantitative analysis: The authors processed a dump of the full history of the English Wikipedia's first nine years. For each of the 108 months from January 2001 to December 2009 and each editor, that editor's activity was described by the following numbers: "the number of edits and pages edited, median [Levenshtein] edit distance and article length change, the number of reverted edits, and reverts done [...., in] four namespaces: encyclopedia articles, article talk pages, policies and guidelines, and policies and guidelines talk pages". A cluster analysis is then performed for each month to group editors into sets of similar editing behavior. The authors report:
"we identify a slow initiation period followed by a period of extremely rapid growth, and, finally, levelling out and a slight decline. In the first phase, there is only a minimal differentiation of contributors into clusters. The second phase of exponential growth is characterized by increasing differentiation of contributors, while the number of clusters stabilizes in the third phase. The statistics provide only a very rough depiction of a complex system, but they certainly suggest that, whatever governance mechanisms have been in place, they have had to deal with dramatically different circumstances over the years." - qualitative analysis: Building on these three phases identified via descriptive statistics, the authors construct "theoretical narrative ... [using] a highly selective representation of empirical material that advances the plot of capability-building", including discussion of the history of policies, processes and events including IAR, 3RR, FAR, bot policy, flagged revisions, the 2005 Nature study comparing Wikipedia's quality with Britannica's, the Seigenthaler affair the same year, etc.
The researchers note that Wikipedia governance has changed significantly over the years, becoming less open and more codified, which they seem to acknowledge as a positive change. The authors' main conclusion stresses, first, that governance could itself be a dynamic, evolving process. Second, that new kinds of governance mechanisms make it possible to create significant value by harnessing knowledge resources that would be very difficult to seize through a market or corporate system. Third, that the lack of a contractually sanctioned governance framework means that people have to learn to deal directly with each other through peer-based interaction and informal agreements, which in turn creates opportunities for self-improvement through learning. Fourth, the authors note that the new type of governance models are constantly evolving and changing, meaning they have a very fluid structure that is difficult to describe, and may be better understood instead as changing combinations of different, semi-independent governance mechanisms that complement one another. Finally, they stress the importance of technology in making those new models of governance possible.
Readability of plastic surgery articles examined
The subject of readability of online patient materials for Plastic Surgery topics was recently assessed by teams from Beth Israel Medical Center at the Harvard Medical School. Readability scores are generally expressed as a grade level: Higher grade levels indicate that that content is more difficult to read. According to the authors, "nearly half of American adults have poor or marginal health literacy skills and the NIH (National Institute of Health) and AMA (American Medical Association) have recommended that patient information should be written at the sixth grade level". The aim of their research was to calculate readability scores for the most popular web pages displaying procedure information and compare the results to the sixth grade reading level recommendation.
Overview
The core author group published two papers, "Online Patient Resources for Liposuction"[2], in Annals of Plastic Surgery , and "Assessment of Online Patient Materials for Breast Reconstruction"[3], in Journal of Surgical Research. The authors concentrated on the topics of "liposuction" and "tattoo information" in one paper, and focused solely on the topic of "breast reconstruction" in the second paper. Readability scores were accessed in both papers, but the breast reconstruction paper added an analysis of ‘complexity’ and ‘suitability’ to more comprehensively evaluate reading level.
For each procedure term topic, websites selected for analysis were based on the top 10 links resulting from the Google search query. The top 10 links were identified as the 10 most common websites for that search term.

Results and conclusions
The authors concluded that the readability of online patient information for ‘liposuction’ and ‘breast reconstruction’ is ‘too difficult’ for many patients as the readability scores of all 20 websites (10 each) far exceeds that of a 6th-grade reading level. The average score for the most popular ‘liposuction’ websites was determined equal to 13.6-grade level. As a comparison ‘tattoo information’ scored at the 7.8-grade level.
Health care information available at the most popular websites for ‘breast reconstruction’ had an average readability score of 13.4, with 100% of the top 10 websites providing content far above the recommended 6th grade reading level . Wikipedia.org readability scores aligned at the higher readability range for both terms, with scores above the 14 grade level for ‘liposuction’, and above grade 15 for ‘breast reconstruction’.
When other metrics such as ‘complexity’ and ‘suitability’ were applied to the Breast Reconstruction websites, the content appeared to be more friendly towards less educated readers. Complexity analysis using PMOSE/iKIRSCH yielded an average score of 8th–12th grade level. In a testament to how images and topography enhance user readability, the breast reconstruction paper also employed the SAM ‘suitability’ formula. This metric concluded that 50% of the websites were ‘adequate’. The SAM formula gives weight to the contribution that images, bulleted lists, subheadings, and video make to the readability of content. Wikipedia.org was found to be ‘unsuitable’ along with Komen.org, BreastReconstruction.com, WebMD.com, and MedicineNet.com.
In conjunction with the ‘readability score’, the PMOSE and SAM metric helped to achieve a more comprehensive view of a patient’s ability to read and comprehend the breast reconstruction material.
Liposuction paper methodology
After articles from the 10 websites with liposuction content were stripped of images and videos, the plain text content was analyzed using ten established readability formulas. These included Coleman–Liau, Flesch–Kincaid, Flesch reading ease, FORCAST, Fry graph, Gunning fog, New Dale–Chall, New Fog count, Raygor estimate, and SMOG. All readability formulas in this paper relied on some combination of word length, syllable count, word complexity, and sentence length. Longer word lengths and sentence lengths compute to higher reading levels. Similarly, words of three or more syllables increase the grade level readability scores. These text-based readability scores do not include the impact that images or graphics have on readers.
In an effort to compare readability scores for a procedure ‘similar’ to liposuction, the authors performed the same type of analysis on the term ‘tattoo information’. Not surprisingly, the query for ‘tattoo information’, a simpler procedure, yielded content with average readability scores of 7.8-grade level.
Based on this wide gap of 5.8 grade levels in readability scores between ‘liposuction’ and ‘tattoo’ literature, the authors pose the question , “So why is this (tattoo) information significantly easier to read than liposuction?” The authors do present good example strategies for rewriting some liposuction content at lower reading levels. However, the authors do not convincingly clarify why the two procedures should have similar low readability levels. The average education levels of the target audience for "liposuction" and "tattoo information" is not well documented in the paper, and it is questionable if they are equal.
According to ASPS statistics, 50% of liposuction patients are over 40 years old. Are 50% of the people seeking tattoos over age 40? While age does not equal reading level, it may certainly give a hint.
Furthermore, the authors downplay the complexity of the liposuction procedure in comparison to tattooing. Liposuction is an invasive procedure performed by a credentialed surgeon and anesthesiologist under IV or General Anesthesia in an accredited outpatient surgery center. The tools, equipment, and anesthetics used in the technique are not simple, common words.
Unlike surgeons, tattoos artists do not require any type of formal medical training or certification. The tattoo procedure does not involve the complexities of pre-operative clearance, fat extraction , fluid and electrolyte regulation, anesthesia administration , or vital sign monitoring. Likewise, the liposuction procedure description is destined to be longer, more technical, and likely requires higher readability levels than tattooing.
Top 10 Google links used in methodology
One consideration which is not discussed by these and other published authors evaluating online content readability, is the fact that Google uses the Dale-Chall and Flesch Kincaid readability formulas in its Penguin algorithm. However, rather than punish high (difficult) readability scores, the algorithm is thought to punish low grade level readability scores. In 2013, the UK analytics company MathSight determined[supp 1] that the Penguin algorithm penalized websites with low grade level readability scores. After the MathSight finding, many SEO experts concluded that Google favors content written at a higher educational level.
In light of this, and regarding the typical methodology of obtaining the data set from Google’s top 10 links, one must question if Google would ever rank a medical content website with a grade 6 readability score higher than a website with a grade 13 readability score. Perhaps even more importantly, most website publishers want what Google wants. Competition is fierce for a spot in the top 10 links. Therefore, as long as online content publishers believe that Google favors well written, well researched, sophisticated content, it might be a tough sell to persuade medical content publishers to oversimplify their content to a sixth grade reading level.
Briefly
- Fukushima discussions in the English and Japanese Wikipedias: Similar to several other pieces of research, this paper[4] looks at social production of knowledge in the context of a single, controversial Wikipedia topic, this time, the Fukushima Daiichi nuclear disaster. The authors compare the discussions in the English and Japanese Wikipedias, noting that (as we would expect) the English one attracts more global audience. Both communities were primarily focused on writing an encyclopedic article, though, contrary to the authors' expectation, it was the English Wikipedia editors who were more likely to raise topics not directly related to the creation of the article. Overall, although the paper is primarily descriptive and does not provide much discussion to enhance existing social theories, it creates a framework to understand the types of discourses among Wikipedia contributors. Other researchers can use the framework to analyze various topics on Wikipedia.
Other recent publications
A list of other recent publications that could not be covered in time for this issue – contributions are always welcome for reviewing or summarizing newly published research.
- "Wikipedia and medicine: quantifying readership, editors, and the significance of natural language"[5]
- "One-shot Wikipedia: An edit-sprint toward information literacy"[6] From the abstract: "In this case study, a Wikipedia-editing activity was incorporated into two-hour one-shot instruction sessions. ... While a great deal of attention has been paid to teaching with multi-week Wikipedia assignments and coursework, evidence from this project suggests that Wikipedia-related activities can be used effectively within much narrower time constraints."
- "Unsupervised biographical event extraction using Wikipedia traffic"[7] From the introduction: "We hypothesise that when a notable event happens to a person, traffic to their Wikipedia page peaks abruptly, and an edit is made to their page describing the event. To explore this hypothesis, a simple outlier-based method is applied to extract peaks (short periods of sudden activity) from Wikipedia page traffic data, which are used to locate page edits which align to sentences contributing to the notability of the page subject."
- "The Internet School of Medicine: use of electronic resources by medical trainees and the reliability of those resources"[8] (blog summary: [1])
- "Wikipedia knowledge community modeling"[9] (book chapter / reference work entry)
- "Domain-specific semantic relatedness from Wikipedia structure: a case study in biomedical text"[10] (book chapter)
- "Wikipedia – challenges and new horizons in enhancing medical education"[11]
- "Coverage of European parties in European language Wikipedia editions"[12]
- "Context-aware detection of sneaky vandalism on Wikipedia across multiple languages"[13]
- "Google and Wikipedia in the professional translation process: a qualitative work"[14] (related paper by the same author)
- "Coordination and efficiency in decentralized collaboration"[15] (conference paper submitted to ICWSM 2015). From the abstract: "we consider the trade-offs inherent in coordination in [decentralized on-line collaboration environments], balancing the benefits to collaboration with the cost in effort that could be spent in other ways. We consider two diverse domains that each contain a wide range of collaborations taking place simultaneously – Wikipedia and GitHub – allowing us to study how coordination varies across different projects. We analyze trade-offs in coordination along two main dimensions, finding similar effects in both our domains of study: first we show that, in aggregate, high-status projects on these sites manage the coordination trade-off at a different level than typical projects; and second, we show that projects use a different balance of coordination when they are "crowded", with relatively small size but many participants."
References
- ^ Aaltonen, Aleksi; Lanzara, Giovan Francesco (2015-06-09). "Building Governance Capability in Online Social Production: Insights from Wikipedia". Organization Studies. 36 (12): 1649–1673. doi:10.1177/0170840615584459. ISSN 1741-3044. S2CID 1629212.
- ^ Vargas, Christina R.; Ricci, Joseph A.; Chuang, Danielle J.; Lee, Bernard T. (February 2015). "Online Patient Resources for Liposuction: A Comparative Analysis of Readability". Annals of Plastic Surgery. 76 (3): 349–354. doi:10.1097/SAP.0000000000000438. ISSN 0148-7043. PMID 25695442. S2CID 6726621.
 / freely available authors' copy
/ freely available authors' copy
- ^ Vargas, Christina R.; Kantak, Neelesh A.; Chuang, Danielle J.; Koolen, Pieter G.; Lee, Bernard T. (2015). "Assessment of Online Patient Materials for Breast Reconstruction". Journal of Surgical Research. 199 (1): 280–286. doi:10.1016/j.jss.2015.04.072. ISSN 0022-4804. PMID 26088084.
- ^ Hara, Noriko; Doney, Jylisa (2015-05-19). "Social construction of knowledge in Wikipedia". First Monday. 20 (6). doi:10.5210/fm.v20i6.5869. ISSN 1396-0466.
- ^ Heilman, James M; West, Andrew G (2015-03-04). "Wikipedia and Medicine: Quantifying Readership, Editors, and the Significance of Natural Language". Journal of Medical Internet Research. 17 (3): –62. doi:10.2196/jmir.4069. ISSN 1438-8871. PMID 25739399.
- ^ John Thomas Oliver (2015-02-09). "One-shot Wikipedia: an edit-sprint toward information literacy". Reference Services Review. 43: 81–97. doi:10.1108/RSR-10-2014-0043. ISSN 0090-7324.
- ^ Alexander Hogue, Joel Nothman and James R. Curran. 2014. Unsupervised biographical event extraction using wikipedia traffic. In Proceedings of Australasian Language Technology Association Workshop, pages 41–49. http://www.aclweb.org/anthology/U14-1006
- ^ Egle, Jonathan P.; Smeenge, David M.; Kassem, Kamal M.; Mittal, Vijay K. (April 2015). "The Internet School of Medicine: Use of electronic resources by medical trainees and the reliability of those resources". Journal of Surgical Education. 72 (2): 316–320. doi:10.1016/j.jsurg.2014.08.005. ISSN 1878-7452. PMID 25487347.
- ^ Jankowski-Lorek, Michal; Ostrowski, Lukasz; Turek, Piotr; Wierzbicki, Adam (2014). "Wikipedia Knowledge Community Modeling". In Reda Alhajj; Jon Rokne (eds.). Encyclopedia of Social Network Analysis and Mining. Springer New York. pp. 2410–2420. doi:10.1007/978-1-4614-6170-8_269. ISBN 978-1-4614-6169-2.
- ^ Sajadi, Armin; Milios, Evangelos E.; Kešelj, Vlado; Janssen, Jeannette C. M. (2015). "Domain-Specific Semantic Relatedness from Wikipedia Structure: A Case Study in Biomedical Text". In Alexander Gelbukh (ed.). Computational Linguistics and Intelligent Text Processing. Lecture Notes in Computer Science. Vol. 9041. Springer International Publishing. pp. 347–360. doi:10.1007/978-3-319-18111-0_26. ISBN 978-3-319-18110-3.
- ^ Herbert, Verena G.; Frings, Andreas; Rehatschek, Herwig; Richard, Gisbert; Leithner, Andreas (2015-03-06). "Wikipedia – challenges and new horizons in enhancing medical education". BMC Medical Education. 15 (1): 32. doi:10.1186/s12909-015-0309-2. ISSN 1472-6920. PMC 4384304. PMID 25879421.
- ^ Yasseri, Taha (25 April 2015). "Coverage of European parties in European language Wikipedia editions". Can social data be used to predict elections?.
- ^ Tran, Khoi-Nguyen; Christen, Peter; Sanner, Scott; Xie, Lexing (2015-05-19). "Context-Aware Detection of Sneaky Vandalism on Wikipedia Across Multiple Languages". In Tru Cao; Ee-Peng Lim; Zhi-Hua Zhou; Tu-Bao Ho; David Cheung; Hiroshi Motoda (eds.). Advances in Knowledge Discovery and Data Mining. Lecture Notes in Computer Science. Vol. 9077. Springer International Publishing. pp. 380–391. doi:10.1007/978-3-319-18038-0_30. ISBN 978-3-319-18037-3.
- ^ Alonso, Elisa (2015-02-13). "Google and Wikipedia in the professional translation process: a qualitative work". Procedia – Social and Behavioral Sciences. 32nd International Conference of the Spanish Association of Applied Linguistics (AESLA): Language Industries and Social Change. 3–5 April 2014, Seville, SPAIN. 173: 312–317. doi:10.1016/j.sbspro.2015.02.071. ISSN 1877-0428.
- ^ Romero, Daniel M.; Huttenlocher, Dan; Kleinberg, Jon (2015-03-25). "Coordination and efficiency in decentralized collaboration". arXiv:1503.07431 [cs.SI].
- Supplementary references and notes:
Reader comments
2015 MediaWiki architecture focus and Multimedia roadmap announced
This past week saw the kick-off of the 2015 MediaWiki architecture focus of improving our content platform. The architecture committee identified three main areas needing improvement:
- Storage: To better separate data from presentation, we need the ability to store multiple bits of content and metadata associated with each revision. This storage needs to integrate well with edits, history views, and other features, and should be exposed via a high-performance API.
- Change propagation: Edits to small bits of data need to be reliably and efficiently propagated to all content depending on it. The machinery needed to track dependencies should be easy to use.
- Content composition and caching: Separate data gives us the freedom to render infoboxes, graphs or multimedia elements dynamically, depending on use case and client. For performance and flexibility, it would be desirable to assemble at least some of these renders as late as possible, at the edge or on the client.
More details are available in the announcement email.
Multimedia roadmap announced
Mark Holmquist, the lead engineer of the Multimedia team, announced this week a change in the strategy of the upload tool they are planning to develop. The new plan involves moving the upload API logic into MediaWiki core and creating an interface for uploading files directly from VisualEditor. A heavily summarized roadmap for the team is:
- A mw.Api.plugin.upload JavaScript API to automatically detect what methods are available for the browser, take a File object or file input, and perform the upload
- Tie together the various JavaScript parts into an Upload object or similar in core, so we can handle it with relative ease in our mostly-UI extension
- An upload OOUI widget can then just use all of those things, and it can live in VisualEditor instead of having to be across a couple of extensions.
Syntax highlighting overhaul
-
 GeSHi (old highlighter)
GeSHi (old highlighter) -
 Pygments (new highlighter)
Pygments (new highlighter)


{kind=link}
{kind=link}
{kind=link}
The GeSHi library used by MediaWiki for syntax highlighting was mostly unmaintained and had a significant performance impact for all page views due to the number of stylesheets it contained. It is being replaced by Pygments, which brings support for 492 new languages, and is more actively maintained. We will lose support for 31 smaller languages, most of which are rather obscure. A full list of language changes is available here. From a performance perspective, this will decrease the amount of time that pages take to load and render (including those that don't use syntax highlighting at all!), but will increase the time it takes to save articles with syntax highlighting by about a tenth of a second. More details are available in the announcement.
Reader comments
Board of Trustees propose bylaw amendments
The Board of Trustees is the "ultimate corporate authority" of the Wikimedia Foundation and the level at which the strategic decisions regarding the Wikimedia movement are made. This May saw through the 2015 Wikimedia Foundation elections, the biennial community process which elects the members of the Funds Dissemination Committee (including its ombudsman) as well as the three community appointees on the Board of Trustees itself. With this year's election cycle now firmly concluded the Board is now in an ideal position to tender changes to its structure ahead of the next one—something it has now done with the presentation of proposed changes to the Wikimedia Foundation's legally binding bylaws. A discussion about the need to do so was being conducted at the Board level as far back as November 2014; following a February trustees meeting a community consultation was organized, receiving over 200K bytes of community feedback (see also Signpost coverage at the time). The changes being proposed now, six months later, are the result of that feedback and of further institutional rumination by the members of the current Board.
The Wikimedia Foundation was legally incorporated just over 12 years ago, on 20 June 2003. The organization's bylaws were first issued that year, with heavy revisions coming in 2006. The current structure of the Board—ten members, three elected from the community, two elected from the chapters, four elected by the trustees themselves for expertise and one founder's seat—came about as a result of a restructuring in 2008. More minor changes have been made from time to time, with two having occurred since the Board began publicizing these changes in 2013: a vacancy amendment tendered in 2013 and a January 2014 amendment extending voting privileges for the three affiliate-selected seats from "chapters" to "chapters and thematic organizations" (which never really has taken off—Amical Wikimedia remains the only so-called "thorg"). The composition of the Board has nonetheless remained more or less the same in the seven intervening years: three members who were on the Board at the time—now-chair Jan-Bart de Vreede, former treasurer Stu West, and founder Jimbo Wales—are even still there now.
The proposed changes touch upon two themes of definitional importance in the movement today. The first is one of diversity: as the original proposal stated, "Our two different community [election] processes draw from similar pools of candidates, and our searches for appointees have identified few people outside of the US and Europe." Some members of the community have raised concern over this in the follow-up to this years' election, pointing out that despite the publication of a pair of letters calling for diversity in candidacy, the end result was the election of a Board that will become predominantly white and, with current trustees Phoebe Ayers and Maria Sefidari now outgoing, mostly male. The second has to do with chapter representation. Because chapter members get to vote as a part of their chapter (in the chapter elections) and then again as members of the community (in the public community elections), under the current schema they are essentially provided a double voting opportunity; nor is there strong evidence that this complexity-inducing bifurcation in voting rights results in the election of trustees distinguishably different from the ones that would otherwise be elected by the community anyway.
Speaking of the goals of its oncoming reorganization process, back in March the Board had to say:
- What we want to achieve
- A continuous process of looking for potential trustees
- Diversity (gender, geography, expertise, background, different Wikimedia experiences)
- Finding talent inside and outside our communities
- Providing governance experience and training to potential candidates in our movement
- Providing lower overhead ways to contribute to WMF governance and advise strategic decisions
- Limiting bureaucracy and/or staff involvement
- Flexible Board composition: e.g., allowing for an extra 1-2 Trustees in some years
- What it could look like
- More flexibility in the number of Board members
- Instead of having an absolute, non-variable number of Board members (currently 3 elected, 2 affiliate selected, 4 appointed, 1 founder), we could change to a more flexible model. For example, we could allow a minimum and a maximum of community-based and external seats, permitting us to add additional seats proportionately depending on the present needs of the Board.
- A standing pool of nominees
- To increase diversity of candidates we could start moving towards input from a nominating committee or more active self nominations to create a pool of qualified candidates. This pool could be the base for a selection by the Board or a mixture of selection by the Board and election by the community.
- Merge community and affiliation seats
- Chapters, thematic organizations and user groups are part of the community. While chapters and thematic organizations have an exclusive right to select 2 members of the Board, they can also participate in the community selection of another 3 members. To level this artificial separation it could be helpful to combine both processes.
The text and effect of the changes is presented in full detail on the proposal's meta-wiki page. So far the changes focus on changes related to the proposal's subtitle: "Term Limits". All board terms will now be for three years, though this will not be fully implemented until the 2017 community elections. A six year non-consecutive term limit has been set, with an exception carved out for the founder's seat occupied by Jimbo Wales; Stu West and Jan-Bart de Vreede, who both violate this limit, have both already indicated that their current term (ending in December 2015) will be their last. A technical exception will be made for current trustee Alice Wiegand, who is to satisfy the six-year limit by serving three consecutive two-year terms (her current second term also ends December 2015, and will be renewed). Additionally the terms of service will now be staggered, with elections cycling across all three of the years of a trustee's service: one community-elected seat and two appointed seats one year, two affiliate seats and one appointed seat the next year, and two community-elected seats and one one more board appointment in the last.
Some illuminating comments from the discussion associated with the announcement:
| “ | To be clear, this is separate discussion from both the challenges of diversity and the number of seats for specific purposes. This is simply a proposed change on term limits because we want to implement those and it has been on the Agenda of the Governance Committee for quite a while. —Jan-Bart de Vreede | ” |
| “ | I do not know where the rationale is written, but this has been discussed for a long time. The main reason for reform is that 2-year appointments are unusual in the nonprofit sector and it would be expected that if the WMF had a stable board, then the appointments should be longer. A major challenge to this idea could be to say that the WMF does not have a stable board. Already the organization has very unusual appointment process through election by organization members, and that is a strong indication that instability should be the norm.
Assuming that the elections are a path to good board appointments, then considering this is a volunteer board and historically has been filled by people without financial means that are commensurate with the responsibility of being on this board, then giving them more time could be a way to increase the chance that they will grow into the position to be effective. Consider any organization which you feel is comparable to Wikipedia, and consider how that organization's board is managed. It will be very different, and this board is very unusual. This board is unusual because of the legacy of unusual circumstances under which it was convened. One of those unusual circumstances was the creation of a founder seat. Wikipedia could have been a one-person project, but then there were concessions granted to the community that there should be several board officers and a lot of instability, then more board officers and more instability, and now there is a trending demand to make this board and WMF governance more like a comparable organization. A problem with this scheme is that it is very difficult to compare the required strange parts of WMF's governance (founder's seat, community elections, chapter seat system) to that of any other organization. —Lane Rasberry |
” |
Brief notes
- Audit subcommittee looking for members: The Audit Committee of the Board of Trustees is looking for community members with financial and accountancy literacy willing to volunteer as members of the Board's audit subcommittee. Members serve on the committee for a one year period, from July 2015 through July 2016. According to the announcement on the wikimedia-l mailing list, "An audit of the past year's financials is carried out August-September, the WMF files its U.S. tax return in April, and publishes its annual plan in June. Time commitment is roughly 20 hours over the course of the year." Interested parties should e-mail Sj.
Reader comments
Turkish Wikipedia censorship; "Can Wikipedia survive?"; PR editing
Turkish Wikipedia warns readers of censorship

The Hürriyet Daily News reports that the Turkish Wikipedia has posted banners on the top of the encyclopedia to warn users that a number of articles are being blocked by the Turkish government. Four articles on human anatomy have been blocked since November 2014 and an article on Turkish politics was blocked this month. The articles are:
- Human penis
- Female reproduction organs
- Scrotum
- Vagina
- Opinion polling for the Turkish general election, 2015
Katherine Maher, chief communications officer of the Wikimedia Foundation, told BirGün that the WMF was working on curbing the censorship, both through legal means and through implementing HTTPS on all its projects (see Signpost coverage). She said, "We are trying to overcome these obstacles in countries where access to information is limited or controlled." She added, "[T]he community of Wikipedia is completely against censorship."
The Turkish government has a history of Internet censorship and issues with Wikipedia in particular. Last March, it briefly banned Twitter after evidence of alleged corruption by high-ranking Turkish government officials circulated in social media. Last September, a cabinet minister used Twitter to complain about how President Recep Tayyip Erdoğan was depicted in an article on the English Wikipedia (see Signpost coverage). (June 19) G
"Can Wikipedia survive?"

On the opinion pages of the Sunday, June 21 edition of the New York Times, Andrew Lih (Fuzheado), professor of journalism at American University, author of The Wikipedia Revolution, and long-time Wikipedia editor, asks "Can Wikipedia survive?"
Lih writes about the challenges facing Wikipedia: the steady decline in editor participation, the low rates of recruitment of new administrators, tensions between the Wikipedia community and the Wikimedia Foundation, and the rise in the use of mobile devices to access the Internet, which are less likely to be used to edit Wikipedia because "it’s simply too hard to manipulate complex code on a tiny screen." Efforts are being made to address these challenges, such as improvements to Wikipedia mobile apps. Lih highlights some positive developments, such as partnerships between Wikipedia and scientific and cultural institutions like the Wikipedian in Residence program. "These are vital opportunities for Wikipedia to tap external expertise and enlarge its base of editors," he writes.
He concludes:
| “ | The worst scenario is an end to Wikipedia, not with a bang but with a whimper: a long, slow decline in participation, accuracy and usefulness that is not quite dramatic enough to jolt the community into making meaningful reforms.
No effort in history has gotten so much information at so little cost into the hands of so many — a feat made all the more remarkable by the absence of profit and owners. In an age of Internet giants, this most selfless of websites is worth saving. |
” |
Lih's article prompted discussion on Wikipedia and Wikipedia mailing lists, as well as press coverage, such as a column from The Guardian's Andrew Brown, who concluded that mobile devices were the reason that "Wikipedia editors are a dying breed". G
Undisclosed paid editing now in the Sunshine

How paid editors squeeze you dry
31 January 2024
"Wikipedia and the assault on history"
4 December 2023
The "largest con in corporate history"?
20 February 2023
Truth or consequences? A tough month for truth
31 August 2022
The oligarchs' socks
27 March 2022
Fuzzy-headed government editing
30 January 2022
Denial: climate change, mass killings and pornography
29 November 2021
Paid promotional paragraphs in German parliamentary pages
26 September 2021
Enough time left to vote! IP ban
29 August 2021
Paid editing by a former head of state's business enterprise
25 April 2021
A "billionaire battle" on Wikipedia: Sex, lies, and video
28 February 2021
Concealment, data journalism, a non-pig farmer, and some Bluetick Hounds
28 December 2020
How billionaires rewrite Wikipedia
29 November 2020
Ban on IPs on ptwiki, paid editing for Tatarstan, IP masking
1 November 2020
Paid editing with political connections
27 September 2020
WIPO, Seigenthaler incident 15 years later
27 September 2020
Wikipedia for promotional purposes?
30 August 2020
Dog days gone bad
2 August 2020
Fox News, a flight of RfAs, and banning policy
2 August 2020
Some strange people edit Wikipedia for money
2 August 2020
Trying to find COI or paid editors? Just read the news
28 June 2020
Automatic detection of covert paid editing; Wiki Workshop 2020
31 May 2020
2019 Picture of the Year, 200 French paid editing accounts blocked, 10 years of Guild Copyediting
31 May 2020
English Wikipedia community's conclusions on talk pages
30 April 2019
Women's history month
31 March 2019
Court-ordered article redaction, paid editing, and rock stars
1 December 2018
Kalanick's nipples; Episode #138 of Drama on the Hill
23 June 2017
Massive paid editing network unearthed on the English Wikipedia
2 September 2015
Orangemoody sockpuppet case sparks widespread coverage
2 September 2015
Paid editing; traffic drop; Nicki Minaj
12 August 2015
Community voices on paid editing
12 August 2015
On paid editing and advocacy: when the Bright Line fails to shine, and what we can do about it
15 July 2015
Turkish Wikipedia censorship; "Can Wikipedia survive?"; PR editing
24 June 2015
A quick way of becoming an admin
17 June 2015
Meet a paid editor
4 March 2015
Is Wikipedia for sale?
4 February 2015
Shifting values in the paid content debate; cross-language bot detection
30 July 2014
With paid advocacy in its sights, the Wikimedia Foundation amends their terms of use
18 June 2014
Does Wikipedia Pay? The Moderator: William Beutler
11 June 2014
PR agencies commit to ethical interactions with Wikipedia
11 June 2014
Should Wikimedia modify its terms of use to require disclosure?
26 February 2014
Foundation takes aim at undisclosed paid editing; Greek Wikipedia editor faces down legal challenge
19 February 2014
Special report: Contesting contests
29 January 2014
WMF employee forced out over "paid advocacy editing"
8 January 2014
Foundation to Wiki-PR: cease and desist; Arbitration Committee elections starting
20 November 2013
More discussion of paid advocacy, upcoming arbitrator elections, research hackathon, and more
23 October 2013
Vice on Wiki-PR's paid advocacy; Featured list elections begin
16 October 2013
Ada Lovelace Day, paid advocacy on Wikipedia, sidebar update, and more
16 October 2013
Wiki-PR's extensive network of clandestine paid advocacy exposed
9 October 2013
Q&A on Public Relations and Wikipedia
25 September 2013
PR firm accused of editing Wikipedia for government clients; can Wikipedia predict the stock market?
13 May 2013
Court ruling complicates the paid-editing debate
12 November 2012
Does Wikipedia Pay? The Founder: Jimmy Wales
1 October 2012
Does Wikipedia pay? The skeptic: Orange Mike
23 July 2012
Does Wikipedia Pay? The Communicator: Phil Gomes
7 May 2012
Does Wikipedia Pay? The Consultant: Pete Forsyth
30 April 2012
Showdown as featured article writer openly solicits commercial opportunities
30 April 2012
Does Wikipedia Pay? The Facilitator: Silver seren
16 April 2012
Wikimedia announcements, Wikipedia advertising, and more!
26 April 2010
License update, Google Translate, GLAM conference, Paid editing
15 June 2009
Report of diploma mill offering pay for edits
12 March 2007
AstroTurf PR firm discovered astroturfing
5 February 2007
Account used to create paid corporate entries shut down
9 October 2006
Editing for hire leads to intervention
14 August 2006
Proposal to pay editors for contributions
24 April 2006
German Wikipedia introduces incentive scheme
18 July 2005
The New York Times reports on claims of paid editing of Wikipedia by employees of the public relations firm Sunshine Sachs. Sunshine Sachs has represented a number of celebrity clients, including Leonardo DiCaprio, Ben Affleck, Barbra Streisand, Guy Fieri, The Jonas Brothers, and Trisha Yearwood. In 2012, Business Insider listed its CEOs, Shawn Sachs and Ken Sunshine as among the "most powerful publicists in Hollywood".
Paid editing without disclosing a conflict of interest is a violation of the Wikimedia Foundation's Terms of Use. Last year, after much community input and debate, the Terms of Use were strengthened in regards to undisclosed paid editing.
The alleged paid editing by Sunshine Sachs was exposed by Pete Forsyth (Peteforsyth), a Wikipedia editor and paid consultant who runs Wiki Strategies, which "provides consulting services for organizations engaging with Wikipedia and other collaborative communities". (The Signpost interviewed Forsyth in 2012 on the subject of paid editing.) Prompted by a Sunshine Sachs email Forsyth received which read "Sunshine Sachs has a number of experienced editors on staff that have established profiles on Wikipedia. The changes we make to existing pages are rarely challenged," Forsyth paid journalist Jack Craver to investigate and write a story called "PR firm covertly edits the Wikipedia entries of its celebrity clients" for the Wiki Strategies blog. The story focused primarily on edits to the article for Naomi Campbell, a Sunshine Sachs client, by one editor identified as a Sunshine Sachs employee. The editor removed a number of references to the extremely poor critical reception of her 1994 album babywoman and other potentially unflattering information.
Ken Sunshine acknowledged to the New York Times that Sunshine Sachs employees had violated Wikipedia's terms of use, but said that all of their staff have now disclosed their conflict of interest. It is not known how many Sunshine Sachs employees have edited Wikipedia, but the user pages of the three accounts mentioned in Craver's story now all have disclosure notifications. The Signpost also found one other account with such a disclosure notice.
The story attracted further coverage in a number of news outlets around the world, including the Daily Mail, India Today and stuff.co.nz.
Last year, a number of prominent public relations agencies committed to "ethical engagement practices" when editing Wikipedia (see Signpost coverage). Despite this, a number of companies still do not disclose their COI editing. For example, a April Signpost report revealed undisclosed advocacy editing by Sony. (June 23) G
In brief

- The threat to Freedom of Panorama, highlighted in the Signpost last week, was the subject of a leading article in The Times on June 24. Under the title "Freedom to Photograph" (subscription) the Times thundered:
- "Next time you take a photo of the London Eye, or the Angel of the North, or any monument, artwork or building in a public place, know this: you are exercising a freedom that is under threat".
- Two days later, on June 26, the newspaper also featured two follow-up letters at the top of its letters page, one signed by Jimmy Wales together with the British Photographic Council, the British Press Photographers' Association, the British Institute of Professional Photographers, Amateur Photographer, the Bureau of Freelance Photographers, the Chartered Institute of Journalists, the Chartered Institute of Public Relations and the Open Rights Group; the second by Michael Maggs, chairman of Wikimedia UK.
- The Times's news reporting on the subject (subscription) was followed up by the online editions of The Daily Telegraph, The Independent, the Daily Express and the Daily Mail. (A tracking page on Commons has more UK political and media echo.) The coverage notably included opposition to the change from a spokesperson for the Royal Institute of British Architects (RIBA),
- "We are concerned that the well-intentioned proposals to ensure that architects are paid for the use of images of their work by commercial publishers and broadcasters would instead have negative implications, and represent a potentially damaging restriction of the debate about architecture and public space."
- As of June 26 a petition to "Save the Freedom of Photography" launched by photographer Nico Trinkhaus on the website change.org had reached over 25,000 signatures in its first three days.
- German Wikipedia is now running black banners above its articles to warn of the threat, and a discussion is open at Wikipedia talk:Freedom of Panorama 2015 as to whether the English Wikipedia should do similarly. The hashtag #saveFoP on twitter has also seen extensive traffic. Jheald

- Visualizing Wikipedia editing: A bar graph of the 30 most edited Wikipedia articles as of March 2015 was created by Ramiro Gómez, based on data from Wikipedia:Database reports/Pages with the most revisions. He posted the graph to the Reddit forum DataIsBeautiful. The Independent noted that "The list has little coherence or order. Some at the top are among the most important things in the world...but others are much more insignificant." It concluded that "the list perhaps says more about the people who are using the site than anything to do with the people being written about." Vox wrote that "In some cases, it's about the level of controversy and the scrutiny a certain topic might receive...Other times, however, it can be based on a topic being extremely dynamic or inspiring a lot of passion." Gómez himself attributed some of the traffic to vandalism, writing "Controversial figures certainly attract people who desparately [sic] try to be funny". (June 24-25) G
- Jimmy Wales asked to return UAE money: The Middle East Monitor sharply criticized Wikipedia co-founder Jimmy Wales for having accepted $500,000 from the UAE government last December, a decision controversially discussed at the time, given the UAE's dismal human rights record (see previous Signpost coverage). The renewed criticism was sparked by a Twitter and email exchange between Wales and Alastair Sloan, the article's author. (June 24) A.K.
- Apparently they all have manifestos: A white supremacist manifesto has been discovered on a website belonging to Dylann Roof, who has been charged with nine murders in the June 17 Charleston church shooting. The manifesto, presumably written by Roof, details the racist opinions of its author and how he came to them, beginning with learning about the shooting of Trayvon Martin. The author writes, "The event that truly awakened me was the Trayvon Martin case. I kept hearing and seeing his name, and eventually I decided to look him up. I read the Wikipedia article and right away I was unable to understand what the big deal was. It was obvious that Zimmerman was in the right. But more importantly this prompted me to type in the words 'black on White crime' into Google, and I have never been the same since that day." (June 20) G

- New offices for Wikimedia Armenia: ArmeniaNow reports on the opening of the new offices of Wikimedia Armenia on Friday, June 19. The new offices are in the Press Building in Yerevan, the capital of Armenia. Serzh Sargsyan, the President of Armenia, toured the offices and participated in discussions about Wikimedia projects in Armenia. Also on hand were Jan-Bart de Vreede, Chair of the Wikimedia Foundation Board of Trustees, Asaf Bartof, Head of WMF Grants and Global South Partnerships, Anna Koval, Manager of the Wikipedia Education Program, and Liam Wyatt, GLAM-Wiki Coordinator for Europeana. Wikimedia Armenia was founded in 2013. Last year, their "One Armenian, One Entry" program spurred Armenians to add thousands of articles to the Armenian Wikipedia. It is currently the 40th largest Wikipedia, with over 170,000 articles. De Vreede told ArmeniaNow that Wikimedia had much to learn from Wikimedia Armenia's efforts. (June 19) G
Reader comments
7,473 volumes at 700 pages each: meet Print Wikipedia

After six years of work, a residency in the Canadian Rockies, endless debugging, and more than a little help from my friends, I have made Print Wikipedia: a new artwork in which custom software transforms the entirety of the English-language Wikipedia into 7473 volumes and uploads them for print-on-demand. I'm excited to be launching this project in a solo exhibition, From Aaaaa! to ZZZap!, at Denny Gallery in the Lower East Side of New York City, on view now through July 2nd.
The two-week exhibition at Denny Gallery is structured around the upload process of Print Wikipedia to Lulu.com and the display of a selection of volumes from the project. The upload process will take between eleven and fourteen days, starting at ! and ending at ℧. During this time, the upload process will be open for all to see around the clock—at least during the first weekend, as the gallery will remain open through the night in recognition that the computer itself works continuously. There will be two channels for watching this process: a projection of Lulu.com in a web browser that is automated by the software, and a computer monitor with the command line updates showing the dialogue between the code and the site. If you aren't able to visit the gallery in person, you can follow the process on Twitter; we will post to the @PrintWikipedia Twitter account after it finishes each volume.
Individual volumes and the entirety of Print Wikipedia, Wikipedia Table of Contents, and Wikipedia Contributor Appendix will be available for sale. All of the volumes will be available on Lulu.com as they are uploaded, so by the end of the upload/exhibition all of the volumes will be available on for individual purchase. Each of the 7473 volumes is made up of 700 pages, for a total of 5,244,11 pages. The Wikipedia Table of Contents is comprised of 63,372 pages in 91 volumes. The Wikipedia Contributor Appendix contains all 7,488,091 contributors to the English-language Wikipedia (nearly 7.5 Million).
It is important to note that I have not printed out all of the books for this exhibition, nor do I personally have any intention of doing so—unless someone paid the $500,000 to fabricate a full set. There are 106 volumes in the exhibition, which are really helpful for visualizing the scope of the work. It isn't necessary to print them all out: our imaginations can complete what's missing.

Books are microcosms of the world. To make an intervention into an encyclopedia is to intervene in the ordering systems of the world. If books are a reduced version of the universe, this is the most expanded version we as humans have ever seen. For better or for worse, it reflects ourselves and our societies, with 7473 volumes about life, the universe, and everything. An entry for a film or music album will pop up every few pages, and the entry for humanism will be located in a volume that begins with "Hulk (Aqua Teen Hunger Force)" and ends with "Humanitarianism in Africa" and the names of battles will fill the 28 volumes with entries that start with "BAT." It's big data that's small enough that we can understand it, but big enough that no human will know all of it. It is small enough that I can process it on a desktop computer, though big enough that each round of calculations, such as unpacking the database into a MySQL database, takes up to two weeks to complete, and the whole build cycle takes over a month. As we become increasingly dependent on information what does this relative accessibility of its vastness mean.
Print Wikipedia is a both a utilitarian visualization of the largest accumulation of human knowledge and a poetic gesture towards the futility of the scale of big data. Built on what is likely the largest appropriation ever made, it is also a work of found poetry that draws attention to the sheer size of the encyclopedia's content and the impossibility of rendering Wikipedia as a material object in fixed form: once a volume is printed, it is already out of date.
My practice as an artist is focused around online interventions, working inside of existing technical or logical systems and turning them inside out. I make poetic yet functional meditations that provoke an examination of art in a non-art space and a deeper consideration of the Internet as a tool for radically re-defining communication systems. For example, I sold all of my possessions online in the year-long performance and e-commerce website Shop Mandiberg (2001), and made perfect copies of copies on AfterSherrieLevine.com (2001), complete with certificates of authenticity to be signed by the user themselves. I made the first works to use the web browser plug-in as a platform for creating artworks: The Real Costs (2007), a browser plug-in that inserts carbon footprints into airplane travel websites, and Oil Standard (2006), a browser plug-in that converts all prices on any web page in their equivalent value in barrels of oil.

I began editing Wikipedia a couple years before I first started working on this project in 2009, though it is not my only engagement with Wikipedia. I'm a professor of digital media at the City University of New York, and I teach with Wikipedia in my classes. I have written about this process, my teaching has been covered on the Wikipedia Blog, and one of my assignments was included in a series of Case Studies on teaching with Wikipedia put together by the Wikimedia Foundation, a function now done by the Wiki Education Foundation. I am co-founder of the ArtAndFeminism, a campaign to increase female identified editorship on Wikipedia and improve the site's articles on women and the arts.
Wikipedia matters to me because it is a collaboratively produced repository of human knowledge made through unalienated labor and kept in a digital commons. Most people are acting in good faith, and amazingly those who aren't can't seem to bring the whole thing down.
This was not a solitary endeavor. I was grateful to work with several programmers and designers, including Denis Lunev, Jonathan Kiritharan, Kenny Lozowski, Patrick Davison, and Colin Elliot. I was also supported by a great group of people at Lulu.com who went above and beyond to support this wild and quite unwieldy project.
If you're in New York, I hope you can come see the show. The show will remain open 24 hours a day through 6pm, Sunday June 21st. We will be hosting a special New York City Wikipedians on Sunday June 21st at 1PM. For those of you far away, you can follow the upload process at PrintWikipedia.com and on Twitter.
- Michael Mandiberg is an artist and associate professor at the City University of New York.

Reader comments
Politics by other means: The American politics 2 arbitration
Clausewitz' pithy summary of warfare as "politics by other means" seems to be the motto of some Wikipedia editors. On the English Wikipedia this struggle is seldom fought more fiercely and at greater lengths than in articles about American politics.
In an earlier arbitration case, American politics, which ended in July 2014, the Arbitration Committee of the time noted: "this is at least the fourth arbitration case in the past year related to American political and social issues" and that new disputes seemed to spring up on the heels of the old. One edit warrior, Arzel, was placed on 1RR (one revert per edit per 7-day period) with the possibility of appeal after one year and every six months after. A mechanism was set up for adding problem articles to discretionary sanctions without the necessity of opening a new arbitration case. In February 2015, by an amendment to the case following further edit warring and incivility, Arzel was topic banned from all articles relating to American politics.
A second bite
The chronic culture of bad faith editing in the topic of American politics continued to present a problem for the community. In March 2015, a case was filed against Collect, who had previously been topic-banned in the Tea Party movement case in 2013. The newly filed arbitration involving Collect finished in May 2015, resulting in Collect receiving a revert restriction and a broad indefinite topic ban from American politics articles.
The Arbitration Committee simultaneously elected to revisit last year's American Politics case, as the lightweight mechanism for creating discretionary sanctions had not been used and no improvement was visible.
In this new American Politics 2 arbitration, which closed on June 19, 2015, the mechanism set up in last year's American Politics case was replaced by discretionary sanctions covering "all edits about, and all pages related to post-1932 politics of the United States and closely related people." The cut-off date was the subject of some debate within the Committee: they also publicly voted on versions of the motion with no cut-off and with a 1980 cut-off, and one Arbitrator alluded to private discussion of the possibility of extending the cut-off date back before the Civil War.
In this case, the conduct of Ubikwit and MONGO was found especially disruptive. Ubikwit was topic-banned, the Committee having noted Ubikwit's previous sanction in the Tea Party movement case in 2013. MONGO was admonished.
Reader comments