
The bad and the good
We all know what the bad is. The 2019-2020 coronavirus pandemic has spread to at least 190 countries, infecting 683,000 and killing 32,100 – and these are just the numbers as of March 29. Tomorrow they will be worse. People throughout the world are being quarantined or ordered into social distancing, bringing economies to a near-standstill. The WMF has gone into work-from-home mode, and all in-person gatherings of Wikipedians have been cancelled.
While any "good" from the last month is relative, Wikipedians have responded well to the pandemic. About 500 articles have been written on aspects of the pandemic, and page views of the three most viewed articles are 1.7 million daily; check this month's Traffic report for details. Several major news sources have praised Wikipedians' response.
- How Wikipedia Prevents the Spread of Coronavirus Misinformation
- The Coronavirus Is Stress-Testing Wikipedia’s Policies
- Meet the Wikipedia editors fighting to keep coronavirus pages accurate
- Looking for information on Coronavirus? Wikipedia it
In the media has some details. WikiProject report has extensive views from Wikipedians on the same topics.
Wikipedia is a go-to resource for information in crisis situations. The Special report and Community view explain why this is so.
There are other stories this month. March has traditionally been a special month for stories on women. The Gallery covers this story beautifully.
In focus explores Wikipedia's coverage of the Jeffrey Epstein story.
So how has the coronavirus affected The Signpost? It has been a difficult month for some of us, but we can't complain. We'll save that for the good months. A couple of planned submissions had to be delayed or arrived at the last moment, which is to be expected in such circumstances. We'll get them published in a month or two. We're in this for the duration. Readers who have been considering submitting articles or suggestions to The Signpost should step up and let your voices be heard. Please start with a note on our suggestions page or email me here.
Stay well.
2018 Wikipedian of the year blocked
Farkhad Fatkullin banned, unbanned, rebanned, re-unbanned on Tatar Wikipedia
2018 Wikipedian of the year Farkhad Fatkullin was banned on the Tatar Wikipedia for a post on Phabricator on August 21, 2019. As of March 29, discussions continue in Tatar, Russian, and English on this page. The Signpost has not been able to contact all parties involved, so this report should be considered preliminary.
In 2018, Jimmy Wales said, "Farkhad is energetically community organizing among Russia's minority languages communities, going far and wide beyond his native Tatar. He is also fluent in English, a fact that has established a bridge between those communities and the wider movement after years of isolation."
Fatkullin's views in September are expressed on his Tatar user page in both Russian and English. He recently told The Signpost that he is "quite busy around Wikimedia Language Diversity (Meta), Wiki-Smart Tatarstan (Wikimedia RU) & wider Wiki-Smart Region (Meta), so I don't at all have time to feel wiki-exclusion."
According to this log Fatkulin appears to have been rebanned and re-unbanned on March 29.
Ssr contributed to this article. —S
Brief notes
- A pilot social media traffic report gives statistics on traffic referred to Wikipedia articles from the social media sites Facebook, Reddit, Twitter, and YouTube. The pilot is expected to last 1–3 months, and may help to design a permanent database of such referrals. One hope is that having such a database may aid in patrolling damaging edits coming from disinformation campaigns on the social media sites. See meta:Research:Social media traffic report pilot for further information and Social media traffic report for the data from March 27.
- Guy is back: The community was notified on March 8 by a family member of requests for adminship (RfA) candidate Guy Macon that the candidate had experienced a health incident on March 3, while the RfA was in progress. The RfA was marked "unsuccessful" on March 5. Guy returned from an editing hiatus on March 12 to say that he was recovering and "As a general response to the oppose !votes, I will be studying them and seeing what I can learn ... don't expect any 2nd RfA any time soon."
- WikiCred, a project started at the WikiConference North America 2019, bills itself as Wikimedians Strengthening Knowledge and News Credibility on the Internet. The Craig Newmark Philanthropies, Facebook, and Microsoft fund the project. WikiCred offers microgrants (from $250 to $10,000) for pilot projects to help support internet credibility using Wikimedia. The microgrants can be awarded to individuals or teams. The first deadline to apply is April 6, 2020.
- New user-groups: The Affiliations Committee announced the approval of this week's newest Wikimedia movement affiliates:
- Wikigrannies User Group (Вики-бабушки "wiki-babushkas")[1] – official language Bashkir
- Wikimedians of Turkic Languages User Group[2] – official languages Turkish and Turkic
- Wikimedians of United Arab Emirates User Group[3]
- Wikimedia Community User Group CEE [Central and Eastern Europe] Spring[4]
- Wikimedians for Sustainable Development[5]
- Myanmar Wikimedia Community User Group[6] – official language Burmese
- New administrators: The Signpost welcomes the English Wikipedia's newest administrators, Cabayi and Lee Vilenski.
- Milestones: The following Wikipedia projects reached milestones this month:
- Ukrainian Wikipedia: 1 million articles on March 22 (details in Ukrainian, details in Russian)
- Dutch Wikipedia: 2 million on March 8
References
- ^ m:Affiliations Committee/Resolutions/Recognition of Wikigrannies User Group
- ^ m:Affiliations Committee/Resolutions/Recognition of Wikimedians of Turkic Languages User Group
- ^ m:Affiliations Committee/Resolutions/Recognition of Wikimedians of United Arab Emirates User Group
- ^ m:Affiliations Committee/Resolutions/Recognition of Wikimedia Community User Group CEE Spring
- ^ m:Affiliations Committee/Resolutions/Recognition of Wikimedians for Sustainable Development
- ^ m:Affiliations Committee/Resolutions/Recognition of Myanmar Wikimedia Community User Group
WikiProject COVID-19: A WikiProject Report
For this issue of The Signpost, I interviewed members of WikiProject COVID-19, to get a community view on the pandemic and how this project is reacting to the outbreak.
The interviewees are Tenryuu, Bait30, Kencf0618, Username6892, MarioGom, Magna19, Gtoffoletto, Bondezegou, and Liz. Special thanks especially to Tenryuu, who was instrumental in helping me gather members of the project.
Please note that The Signpost is not encouraging new editors to edit coronavirus related articles: in the words of one of the interviewees Liz, It's not a good place to learn, it is very unforgiving. Edits have to be completely accurate, it's not an area where we can tolerate mistakes. Editors that are completely new to Wikipedia are not likely to have a positive experience. They should learn the practices and guidelines in quieter areas of the project where they can make mistakes and learn from them.
Can you give us a little bit about why you normally do/what topics you edit on Wikipedia?
- Tenryuu: Normally I work with the Guild of Copyeditors in copyediting articles for better structure, flow, spelling, and grammar. Topics are varied depending on what people request and/or what is in the backlog.
- Bait30: I like to do more of the smaller tasks; I don't really enjoy actual writing that much. I find myself going on these sort of edits streaks. For example, I was filling the {{album ratings}} template on a bunch of albums for a while. I also went around updating academic journal Impact factor scores and even fixing a lot of improperly formatted musical artist infobox images. I also sometimes contribute to AfD discussions. I just like to help out where I can.
- Kencf0618: I am all over the map.
- Username6892: Normally, my scope is transport-related articles, specifically those relating to the Greater Toronto Area.
- MarioGom: I usually work on articles related to politics and Socialism. I also spend a fair amount of time dealing with integrity (e.g. WP:COIN) and bias (e.g. Women in Red) issues.
- Magna19: I normally edit science and boxing articles, just because these are the things I know the most about.
- Gtoffoletto: Anything. Mostly science/technology related. But I tend to go deep on a topic and focus on that for a while and then move on.
- Bondegezou: I mostly do edits around UK politics and elections, or around the music I like, but I also do edits related to my work in health research.
- Liz: I'm an admin and I spend most of my time doing admin work, particularly deleting categories and redirects that are no longer needed. I use to spend most of my time categorizing pages & categories before I became an admin.
What motivated you to join this Project? Is it different than the topics you usually cover?
- Tenryuu: The worldwide spread of it and how it's affecting my city is what gave me reason to join after Another Believer's invitation. It has made me look for sources and use them to cite ideas in the articles to keep them up to date.
- Bait30: Obviously, the coronavirus-related articles are the most viewed articles on Wikipedia right now. With that comes a lot of edits, which in turn can lead to a lot of problems. For example, broken links/citations, content forking, and MOS issues. And then, because the volume of edits, it becomes difficult to go through the edit history to figure out what caused the error in the first place. I figured it would be better to join the Project in order to be a part of a more centralized "system" for editing these articles rather than just trying to edit things by myself.
- Kencf0618: I have worked extensively on our Swine Flu timeline (we were shipping out body bags for that one), and began our COVID19 timeline. The global scope and local impact of this public health catastrophe is unprecedented in living memory – it's a long time since the Spanish Flu.
- Username6892: When I first found out about this project, I was starting to edit the COVID-19-related articles. I joined because I knew the pandemic was going to last longer than I previously thought (which may cause more views for more time) and I was getting very interested in this topic at a time when schools were closed so I had much less else to really do at that time. With information coming out all the time and vandals trying to make it worse, why wouldn't I try to help?
- MarioGom: Being in confinement and unemployed has left me with a lot of spare time. I checked COVID-19 statistics around the world everyday and started to update them on Wikipedia when they were outdated. Previous familiarity with research and reliable sources is helpful for my COVID-19-related tasks. Other than that, it is quite different from my usual Wikipedia work.
- Magna19: The sheer scale of it needs a lot of editors.
- Gtoffoletto: It's the greatest crisis ever faced by my generation and wanted to contribute to solving it by ensuring accurate information is readily available. I'm also from Milan, Italy. A region that has been hit particularly hard and "early" in the Western world.
- Bondegezou: I work in public health, including now on COVID-19, so I was obviously interested in what Wikipedia had to say on the subject. Projects can be a great way of bringing editors together.
- Liz: I became concerned in February about possible vandalism in COVID-19 articles so I started adding them to my Watchlist. Then I added more and more pages, there must be over 400 at this point. Joining the WikiProject seemed like the next logical step in order to stay informed about any standardization on the subject. One can't effectively patrol for vandalism and misinformation if you don't know the correct terminology or expectations. I have never worked on medicine-related articles so I'm still learning a lot from editors who are more experienced in this field.
What, in your opinion, is the main goal of this Project?
- Tenryuu: To provide up-to-date, readily confirmed, and factual information on the pandemic and the effects and responses it is having on all of our homes.
- Bait30: To be a place where Wikipedia editors can collaborate to provide up-to-date information about COVID-19 for Wikipedia readers.
- Kencf0618: As above.
- Username6892: To organize and standardize the format of these articles while providing the most reliable and up-to-date information possible.
- MarioGom: Nothing to add to previous answers. For me, personally, providing reliable and up-to-date statistics.
- Magna19: As per all above.
- Gtoffolletto: Totally agree with User:Tenryuu
- Bondegezou: Username6892 says it best for me.
- Liz: To standardize sources for case counts and terminology on the subject so that they can be consistent over the hundreds of articles that have been recently created on aspects of COVID-19 and how it manifests across the world. Also, it helps to draw attention to COVID-19 pages that need some urgent attention.
Is working on articles relating to sickness and disease different from covering something like biology or military history? If so, how?
- Tenryuu: I can't speak for covering military history or biology in general, but with how many people come to Wikipedia to get information on this ongoing pandemic, it is important to get facts from reliable sources so that people are properly informed and not needlessly panicked.
- Bait30: I wouldn't say it's totally different. The pandemic can be looked at from multiple angles, from medicine to economics, politics, and pop culture. Because of that, you can join this Project and edit things in your area of expertise, and people with a completely different skill-set can help out with the other things you're not used to.
- Username6892: If you look at biology (and most other science-related topics), it takes a while for each discovery to be made. The articles don't have a large amount of views or edits unless a new discovery is made. Updates don't normally happen often in those fields. In this current pandemic, there are many updates every day so people will come every day to check what the latest case numbers are and what the government and other institutions are doing about it, so editors have to make sure that info is reliable as well as up-to-date every day.
- MarioGom: It is quite similar, although the bar for reliable sources is higher (WP:MEDRS). I don't touch any purely medical content anyway.
- Magna19: Not sure about military history, but it's quite similar to biology just as it has a lot of biology in it. Lots of things that need to be medically correct by the proper sources. Magna19 (talk) 19:16, 24 March 2020 (UTC)
- Gtoffoletto: Yes, very different. The consequences for inaccurate, misleading or imprecise information can be serious.
- Bondegezou: In a way, the same basic principles of summarising reliable information clearly still apply, but it matters more if you get it wrong because of how someone might be acting on what is written. That is particularly true when we're dealing with a pandemic where our only current weapon against it is behaviour change.
- Liz: When I was younger, I worked as a copywriter of legal articles that were posted online for law firms. I was extremely conscious of the fact that people might be reading them for free legal advice and how careful I had to be in my use of language. This experience reminds me of that. In this case though, I'm not the content creator, as I have no medical background, I'm just checking pages & edits for possible vandalism or inappropriate content.
Do you see this Project lasting after the COVID-19 disease goes away?
- Tenryuu: For a bit. I imagine there would be adding the aftermath of COVID-19 in each region and improving data collection and article layouts. Of course, due to the nature of the topic it covers, I consider this an ad hoc project that will eventually lose its relevancy once the virus is properly handled and eradicated. That's the hope, anyway.
- Bait30: I can definitely see this project lasting, at least for a bit, after the disease goes away. This pandemic has caused entire countries to shut down and changed the lives of many people and I don't think there is another WikiProject that has the same global scope. After a while though I do expect the Project to die down and see different Projects take over the different aspects of the pandemic (i.e. expect to see WP:MED become the place to talk about the disease or WP:USA become the place to go for its impact on the United States).
- Kencf0618: This project shall never end.
- Username6892: The answer to this question really depends on how large this outbreak becomes. As of now, I would say it will probably last a couple of years before eventually merging into WP:MED, though if the pandemic is larger than I expect, I could see it lasting much longer (perhaps until the next pandemic).
- MarioGom: I expect a gradual decrease of activity over time. At some point it will become either inactive or maybe merged into another project.
- Magna19: I certainly don't see the project going away any time soon, just due to the unprecedented nature of it all.
- Gtoffoletto: Not sure how long this ordeal will last at the moment. Still insufficient data to determine how it will end. If the pandemic is defeated it will gradually go away.
- Bondegezou: This virus isn't going away any time soon. Even once we've come out of the pandemic phase, this will still be a disease that affects people's lives, and we don't know what the long-term impacts of infection or the social changes we're seeing are. There is going to be plenty to do for years.
- Liz: There will probably always be a need for this WikiProject although I expect participation to decrease as the pandemic subsides. This is pretty typical with all WikiProjects which seem to have a natural lifecycle of initial enthusiasm that turns into a focus on the maintenance of articles. I expect there to be future pandemics and natural disasters that could use this WikiProject as a template for their own topics.
What words of wisdom, if any, would you give to new/inexperienced editors looking to join the Project, as I am sure there are many?
- Tenryuu: Because information is constantly coming in at a high rate, and some may not be factual (e.g., treatments that are purported to prevent infection or even treat it) so a decent level of fact-checking is required. There's nothing improper about finding new information, but I believe that inexperienced editors should discuss it on the relevant talk page with more experienced editors so that it may be vetted and changes can be made before it is potentially added to the article.
- Bait30: Don't be afraid to collaborate. If you have questions, ask them! If you get reverted, don't be discouraged. Discuss it on the talk page. We all just want to provide the best information to our readers and collaboration is the best way to do that.
- Kencf0618: Ooof. Let's wade into WWII, shall we...? I would advise new editors to specialize in what they know on the ground – local coverage, in other words.
- Username6892: As a less-experienced editor myself, I normally edit articles which provide local coverage for me, because I am more knowledgeable in that area, but asking questions on the talk page is a good idea, too. Especially if you want to make a major change, it is good to get the opinions of others before doing it.
- MarioGom: Keep calm. Be civil. Remember that we are volunteers and there is no deadline.
- Magna19: Just stick to the best, most authoritative sources and find as many of them as possible.
- Gtoffoletto: WP:NOTNEWS. Don't rush to put everything in. Try to avoid news reports and focus on accurate scientific sources.
- Bondegezou: What Gtoffoletto said.
- Liz: I don't want to discourage participation in this WikiProject but, at this point, if you have some concern with how material is being presented, it has probably already been discussed, possibly multiple times on article talk pages. Do not propose drastic changes or page moves without becoming familiar with talk page archives. Because the pace of edits and discussion has been moving so rapidly over the past three weeks, I'd encourage new editors to find a quieter place to learn editing because the world of COVID-19 articles can feel overwhelming. There are 6 million other articles that could use your attention, too.
What are some of the Project's main goals besides simply improving articles?
- Tenryuu: As a result of collecting the correct data and reporting accurately, reducing global panic and informing readers about pertinent information.
- Bait30: To inform our readers. People need to know the true scope of what's going on. Not just location-wise, but also field-wise. By that, I mean that the sports-minded people should be informed about the science of this disease, the scientists should be informed about the socioeconomic effects of this disease, etc.
- Kencf0618: The BBC's live rolling coverage (hard to keep up with!) today has a bit explaining exponential growth and vectors in terms of football (soccer) passes, so yeah...
- Username6892: To get the most up-to-date and reliable information, as well as making sure the articles don't fall to vandalism. There are many articles on the subject, so having a project on it makes it easier for us to make sure all of them are reliable and up-to-date in terms on cases and response efforts (Especially if the government announces a lockdown).
- Magna19: To ensure that real-world consequences of the article are the right ones, but not letting that be the primary reason for any edit, it also has to be in line with the sources. See the issues surrounding the current lead, for example.
- Gtoffoletto: Keeping things organised. There is and will be a huge rush of readers/editors. We must maintain order and efficiency in communication and collaboration.
- Liz: Accuracy and also educating editors and readers. We see some people who come to the pages with their own concerns about COVID-19 or who are trying to promote their own pet theory/point of view. This is misplaced, as we are focused on writing, updating & refining articles, but it's natural for readers to come looking for more information or trying to share what they believe might be helpful (but often isn't).
Do you have any last words you would like to share with our readers?
- Tenryuu: Don't panic or underestimate the virus, keep yourself prepared with the months to come, and stay in touch with friends and family for moral support. Go out as seldom as you can, and take proper precautions for you and others if you are heading out.
- Bait30: Listen to the experts. Get your information from a multitude of sources. Do your research. Be informed. The pandemic is getting worse and worse because people are not doing those things.
- Kencf0618: As per George R. Stewart's Earth Abides, we are going to keep this network running for as long as possible. Ours is an information network; he used power stations and water supplies as exemplary examples. We shall die and live at our stations.
- Username6892: Nobody knows what will happen next, so underestimating is dangerous and panicking is often useless. Those in the medical field know what is needed to get through this pandemic, so listen to them instead of panicking or going to the beach (an easy way to increase your chances of infection) during this time.
- MarioGom: Don't trust those who say this is
just another flu
or said that until recently. Be responsible: keep social distance, reduce contacts, stay home if you can afford it, prepare yourself but do not panic buy and hoard. Do this even if your Government is not forcing you to do it (yet).
- MarioGom: Don't trust those who say this is
- Magna19: Stay indoors, learn from the Chinese response, keep the mind active and finally, hope for a vaccine.
- Gtoffoletto: This will affect the whole world. Let's stay united. We are all in this together. Have faith in science and we will make it together.
- Bondegezou: If you want advice on what to do, listen to your local health authorities. If you want to learn about the background to what is going on, we've got some interesting articles for you.
- Liz: I hope this doesn't need to be said but don't rely on social media for accurate medical information and advice. There are hundreds, possibly thousands, of editors working to improve Wikipedia's coverage of COVID-19 to make it reliable and accurate. But, there are also hundreds of articles on this subject and we are sometimes spread thin. We're all volunteers and doing the best job we can with our time & talents. Please join in the effort and help improve Wikipedia on subjects you are knowledgeable about. Join us! If you find yourself temporarily out of work or out of school, it's great to have the feeling that you are contributing to such a worthwhile project.
Wikipedia on COVID-19: what we publish and why it matters


Wikipedia is among the most requested, published, accessed, and consulted sources of information on coronavirus disease 2019, also called COVID-19. Responsible media planning to communicate general-interest information for COVID-19 or any future crisis includes recognition of Wikipedia's position in the global media environment, what Wikipedia is, and why Wikipedia matters.
Wikipedia's volunteer editors ask the world to identify the most reliable authorities who have published the best information. With these sources available, wiki editors invite everyone to join them in summarizing and citing this content to develop the Wikipedia articles which people read. In this way, readers everywhere get access to information and a public and permanently archived editorial process which anyone can join, review, and critique. Anyone in the world who knows of any expert organization with general reference information to share in any language can encourage that organization to take advantage of Wikipedia's broad reach to share their content. Otherwise, any supporters of an organization's good content can summarize and cite that information themselves in Wikipedia.
Wikipedia is the world's central general information resource

Wikipedia is popular because Wikipedia articles have a high rank in Internet search results. Many journalists, policymakers, health commentators, and medical students read Wikipedia articles directly because they use Wikipedia as a starting point to orient themselves to new topics. Many physicians have patients who read Wikipedia, and consequently, physicians read Wikipedia to understand what information is in public circulation. Because Wikipedia influences the media environment in every field of expertise, any organization which seeks to share information broadly with the public is a particular stakeholder in the scope and quality of Wikipedia content. Wikipedia relies on universities, research institutes, and cultural partners to publish excellent information which Wikipedia can cite, and those organizations in turn may take advantage of Wikipedia's media reach to accomplish their own communication goals for distributing and disseminating their information to the largest audience which the Internet has to offer.

The audience who reads Wikipedia are the people who use search engines including Google, Bing, and DuckDuckGo. More recently, virtual assistants including Google Assistant, Siri, and Amazon Alexa have been answering questions using Wikipedia and Wikidata content. Third-party media through platforms including YouTube and Facebook both direct people to Wikipedia and serve the Wikipedia content to users in their platform. Wikipedia is central to most everyone's experience of using the Internet. Wikipedia has billions of readers,[a] so virtually everyone in the world is within Wikipedia's media influence.
Wikipedia's traffic reports are available to everyone

Articles for the COVID-19 pandemic in English, 中文, فارسی, italiano, русский, हिन्दी, 한국어 and more than one hundred other languages are all part of Wikipedia as a multilingual hub and center for establishing global census in information sharing. As Wikipedia is a free and open project, the traffic report for every Wikipedia article in every language is free and open data for everyone to examine. These reports can help organizations to evaluate the usefulness of publishing in Wikipedia. Conventional communication investment assumes that an expert organization will be able to produce quality information at low cost, but then pay for expensive advertising and outreach to drive readers to their website or insert their content as advertising into existing reader communication channels. With Wikipedia, the audience reach is predictable as the people who use Internet search for gathering information. Consequently, Wikipedia's major challenge is in identifying and acquiring content and collaborations with organizations which will share it. Any organization which is engaged in global-scale public benefit communication, such as for global health, can use Wikipedia traffic reports to compare the pageviews to existing Wikipedia articles with their other options through other media channels.
Three popular Wikipedia audience metrics reports are "Pageviews", which is the traffic to a single article in a single language; "Massviews", which is the traffic to any number of articles in one language; and "Langviews", which is the traffic to a single article in every available Wikipedia language version. All of these are variations of the Pageviews Analysis tool, which itself is a part of the broader practice of wiki traffic reporting.



Three main COVID-19 articles: disease, virus, and pandemic

Wikipedia's most popular articles on COVID-19 are for the disease in the human body, Coronavirus disease 2019; the virus, Severe acute respiratory syndrome coronavirus 2; and the outbreak, 2019–20 coronavirus pandemic. This scope of coverage is already highly unusual, as writing about the disease requires careful summary of medical articles, and writing about the virus requires explaining topics in computational biology to the general public; and a narrative of the pandemic comes from people in every country collaborating to compile their culture's best reports and journalism. While many specialized publications may have deep coverage of one of these, and journalism gives overviews of these, Wikipedia is an unprecedented mix of both. In Wikipedia, the target is to present articles in specialized fields which are both accurate enough to be useful for experts to use, and accessible enough for any curious typical person to gain enough understanding to inform their own decisions – and to edit related Wikipedia articles.

Consider the Wikipedia article on the virus. Wikipedia is uncommon or alone among all popular media sources for its attempt to summarize and cite academic journal articles in the scientific field of virology, molecular biology, and genetics. Of the 90 sources which Wikipedia editors currently cite in the article, 40 are to materials published in academic journals. The Wikipedia community's intent here is to bring the best available information to the public when people ask for it, and in the case of COVID-19, people who have never before asked for information from academic journals are getting science articles on demand right here. Readers can even click through and read those research articles if they are available to the public.
Subtopics: locations, people, timelines, and social issues


Almost every country in the world has its own national story about how COVID-19 changed the lives of its people and the activities of its society. Wikipedia has individual articles to present and preserve these stories for more than 200 countries and regions. These various articles seek to collect and cite original local media sources in local languages wherever possible so that the coverage for a particular place matches the reporting and concerns of the people who had the local experiences. Each regional article is also a point of connection by means of which Wikipedia editors organize multilingual collaboration. While English Wikipedia is the most popular language version globally, for any given language community, people routinely choose to read and edit the specific language versions of Wikipedia for their own languages. Wikipedia editors who can translate two or more languages routinely carry information across language sources into other languages of Wikipedia. A common motivation for editors doing this is to share the concerns and wishes of their culture with a wider global audience.
_(cropped).jpg)
The most popular single article type in Wikipedia is the biography. When a person has been the subject of media attention, then Wikipedia editors can cite those media sources and create a biography. Wikipedia's curated COVID-19 collection of biographies includes prominent researchers and scientists, the politicians who are issuing policy decisions, and people who gain attention for their COVID-19 infections. In many cases, these articles began in the local language version Wikipedia of the subject's country of origin, but once anywhere in Wikipedia, editors will translate these biographies into local languages.
English Wikipedia editors deem more than 400 articles worth managing in the COVID-19 content portfolio. Other popular topics of articles about COVID-19 include compiling timelines, tracking social issues such as the pandemic's socio-economic impact or xenophobia, and countering misinformation, along with various medical concepts like COVID-19 testing or efforts towards a COVID-19 vaccine.
Illustrations and multimedia for every topic
_-_cropped.jpg)
Wikipedia is more than a plain text encyclopedia: some editors volunteer their time curating the text, while others perform other necessary functions such as illustration and photography, copyediting, community organizing, data science, quality control, and administrative tasks.
For supplementary media to illustrate their articles, the encyclopedia writers look to Wikimedia Commons, which is the Wikimedia sister project curating non-text media such as the photos which illustrate Wikipedia's text encyclopedia articles. The typical source of photography is the volunteer photographer who takes a picture wherever they are in the world and shares it in the Wikimedia platform with a free and open copyright license for anyone to reuse. Photography itself has its own subcultures, and for example, there is a culture in photography of people who like to take photos of ships, landscapes, and people.

Part of the COVID-19 story is how cruise ships became a vector for spreading infection, and a natural experiment at that. Many people find huge vessels to be interesting, so in advance of COVID-19, Wikipedia already had articles with photographs of the cruise ships which were the sites of infection. For example, in March 2020, the cruise ship Diamond Princess had passengers who died of COVID-19. A Wikipedia editor created the article for this ship in 2005 and people have been photographing and sharing photos of this ship for years in many countries as documented in a Wikimedia Commons gallery. Wikipedia is the only media outlet which prepared for COVID-19 by documenting and photographing cruise ships 10 years before the outbreak, and Wikipedians also solicited and received feedback from nautical experts to manage these articles through WikiProject Ships and related activities like a three-day workshop dedicated to writing German Wikipedia articles about ships and marine culture.
The source of portraits is typically an encounter between a Wikipedia editor and a person of interest. The United States is one of only a few nations that are applying public domain copyright status to its output, which is why Wikimedia curators can re-purpose some medical illustrations from the Centers for Disease Control as Wikipedia illustrations. Many sincere graphic designers also assist Wikipedia by attaching free and open copyright licenses to their illustrations of abstract concepts, which would be challenging to portray otherwise.
Ebola in 2013, Zika in 2016, and Wikidata every day

Wikidata is the structured data knowledge base which complements Wikipedia and which, like Wikipedia, anyone can edit. Whereas Wikipedia presents general reference prose, Wikidata can answer questions about the articles in Wikipedia as a whole. For example, Wikidata can quickly generate the list of people who have died of COVID-19 and also have a biography in any language of Wikipedia. With this aid, people can create a Wikipedia article in any language reporting a death in any country, and everyone else in the world can gain some knowledge of it or translate more information.

Every article in Wikipedia gets a corresponding Wikidata item. From this point, Wikidata is the hub of Wikimedia cataloging, organization, and query across all languages. For example, Wikidata labels the COVID-19 pandemic (Q81068910) as an "instance of a pandemic". A "pandemic" is a subclass of disaster, so now COVID-19 outbreaks will appear – whenever and wherever someone includes them in Wikipedia/Wikidata – on the automatically generated maps and timelines of WikiProject Humanitarian Wikidata. The wiki community logs both present and historical outbreaks, wildfires, plane crashes, and mass shootings in Wikidata for anyone to query by disaster type, location, number of people affected, or any other descriptor of the sort which wiki editors would use in writing about an occurrence.
Much information about disease outbreaks comes from academic journals, which are the scholarly publications of researchers. Prior to Wikipedia, most people who read academic journals were university professors and students or experts in a field. Since the establishment of Wikipedia, the wiki community has taught the world more broadly that people who make claims should cite reliable sources, and that informed citizens can establish consensus to distinguish objective truth versus fake news, and that instead of anyone citing Wikipedia, fact-checkers should inspect and cite the original sources which Wikipedia itself cites. Wikidata catalogs the source metadata of citations in the WikiCite project. Once these citations are available in Wikidata format, then anyone can query these publications to find the best sources to cite in Wikipedia or for research in any context. Anyone who wishes to review the WikiCite collection of information may review and curate COVID-19 information about the disease, the pandemic, and the virus.
The encyclopedia which anyone can edit
The Wikimedia community of volunteer editors takes its central media role in the information environment seriously. Just as seriously, Wikipedia editors want Wikipedia to be a friendly and civil environment where everyone can peacefully collaborate. Anyone interested in learning more should create a Wikipedia account and edit articles immediately to experience the culture for themselves. Constructive alternatives to editing include posting comments on Wikipedia talk pages, discussing Wikipedia with friends and colleagues, encouraging your local schools and knowledge centers to teach and edit Wikipedia, and praising anyone who demonstrates an interest in the importance of citing sources. The companion piece to this article, "Wikimedia community responds to COVID-19", tells some of the stories of the Wikipedia community organizations who have contributed to the pandemic coverage.
Footnotes
Blocked in Iran but still covering the big story
Last month in this column we couldn't find a theme for February's news coverage of Wikipedia. There was a lone article on the COVID-19 outbreak, "On Wikipedia, a fight is raging over coronavirus disinformation" by Omer Benjakob in Wired on February 9. This month it's almost all COVID-19.
COVID-19 and Wikipedia
- Iran Blocks the Wikipedia Amid Coronavirus Crisis, Says Net Group from the AP via the March 3 Haaretz. Only the Farsi Wikipedia was involved according to the group NetBlocks.
- "How Wikipedia Prevents the Spread of Coronavirus Misinformation" by Noam Cohen on March 15 in Wired was one of the first of many COVID-19 related news stories about Wikipedia this month. More stringent rules are being applied to prevent the spread of misinformation, according to Cohen.
[Wikipedia] has developed a personality, a purpose, a soul. Now, as the new coronavirus outbreak plays out across its many pages, we can see that Wikipedia has also developed a conscience.
- Compare this article to his 2014 article on "Wikipedia Emerges as Trusted Internet Source for Ebola Information" in The New York Times.
- "The Coronavirus Is Stress-Testing Wikipedia’s Policies" by Stephen Harrison in Slate, March 19, emphasizes the importance and difficulty of using Wikipedia's policies and guidelines in an unprecedented situation. What does "the encyclopedia that anyone can edit" mean, when 2,100 editors have edited coronavirus articles and some articles are semiprotected? Policies and guidelines covered include "not news", "reliable sources" and "verifiability".
- "Meet the Wikipedia editors fighting to keep coronavirus pages accurate" in the March 24 Daily Dot concentrates on the sources of misinformation – inexperienced editors, medical studies that don't pass the "smell test", conflict-of-interest editors such as those working for drug or vaccine developers.
- "Looking for information on Coronavirus? Wikipedia it" by Roshni Majumdar in India Today, March 20. Indian editors just started the project "Special Wikipedia Awareness Scheme for The Healthcare Affiliates" or SWASTHA in December to translate Wikipedia's health content into 10 regional languages. Over 500 million people will be using these languages on the internet by next year. It looks like they have a head start now.
- "Wikipedia has COVID-19 information in Bangla, Hindi, Tamil and 6 other Indian languages" in the Hindustan Times follows up on the above story on March 27.
Zika research in the time of COVID-19
- "The impact of news exposure on collective attention in the United States during the 2016 Zika epidemic" by Tizzoni et al was published on March 12 in PLOS Computational Biology. Page views in the US of Zika-related Wikipedia articles such as 2015–16 Zika virus epidemic were highly correlated with the timing of news coverage, but not to the incidence of the disease in particular areas.
- "Wikipedia research on diseases strongly synchronised with news coverage" in Engineering & Technology on March 13 does a good job translating the academic paper to more normal language.
- "Like Zika, The Public Is Heading To Wikipedia During The COVID-19 Coronavirus Pandemic" Forbes.com contributor Farah Qaiser wrote on March 18, trying to draw parallels with the COVID-19 pandemic.
How many Wikipedians can you quote in one story?
On March 7, before COVID-19 became the only story in the news, Alex Pasternack,, who claims to be a Wikipedia editor, quotes at least nine editors in his FastCompany article, including Jimmy Wales, Ryan Merkley, DQUACK02, Cgmusselman, an arbitrator, more than one administrator, and some editors without advanced permissions. A couple of academics were also quoted. Compared to the three love letters Wikipedia received in the media last month, the article is quite realistic describing both our achievements and our challenges. It mentions vandalism, political articles, "one of the most trusted sites on the internet," debunking conspiracy theories, conflicts of interest, paid editing, thousands of small donations, the struggle to retain new editors, biting the newbies, left-wing bias, a Byzantine body of policies and guidelines, assume good faith, and ArbCom. The last several paragraphs are just as densely packed with information, until he slows down for the conclusion. There he goes into detail about his experiences with the new gamified project, WikiLoop Battlefield. He even won a prize there – something like a barnstar.
Women's biographies
March has been a time of many articles on the theme of women's biographies and edit-a-thons. This year however, many edit-a-thons were cancelled and news coverage moved to COVID-19.
- "Filling in the gender gap on Wikipedia" in Fortune covers editing women's biographies, while focusing on Earlham College. Wikipedia Lacks Profiles Of Women. These College Students Are Changing That from Cincinnati Public Radio also focuses on Earlham.
- Did 100 new women's biographies in Brussels sprout? The Brussels Times states that was the goal of the March 5 Wikithon.
- Texas Public Media reports on an edit-a-thon sponsored by Artpace and the San Antonio Museum of Art lets participants know how difficult it can be to find information and properly write articles.
- "Art + Feminism Edit-a-thon teaches Wikipedia editing to students" from the Indiana Daily Student
- "Wikipedia project promotes women artists" in Cornell Chronicle
- The University of North Carolina at Chapel Hill hosted its sixth annual Art + Feminism edit-a-thon as reported by The Daily Tar Heel.
- The Jakarta Post covers efforts by Wikimedia Indonesia and the Swedish Embassy in Jakarta to close the "WikiGap", including recruiting new women editors and translating articles in English into Indonesian and Sundanese.
- High Museum to host virtual Wikipedia edit-a-thon to boost entries about women adapting to social distancing. Ditto for Boston College.
In brief
- BroBible – a site that emphasizes the Bro over the Bible: Here Are The 15 Most Interesting Things I Learned On Wikipedia During My First Week Of Self-Isolation joins an increasing number of stories where the author lists "weird" Wikipedia articles. Matt Reigle's list includes actor Norman Lloyd, whose career so far spans 1923–2015; animated character Oswald the Lucky Rabbit whose career spans 1927–2015, and the Greenland shark which can live to be 500 years old.
- Battle of the macrons: Debate about Māori words on Wikipedia ends: Place names in New Zealand based on the Māori language will now get macrons or diacritical marks. Folks in Paekākāriki should be happy.
- Britney Spears enters Wikipedia's athletic records: Her claim to have shattered the 100-meter dash record by four seconds was briefly listed in Wikipedia (Uproxx)
Do you want to contribute to "In the media" by writing a story or even just an "in brief" item? Edit next month's edition in the Newsroom or leave a tip on the suggestions page.
Rethinking draft space
Draft space: success or failure?
The Draft namespace was created in 2013 as a centralized location for Articles for Creation (AfC) submissions, after the idea was endorsed by the community in a request for comment on the village pump. The original rationale for its creation was that the creation of the namespace would make it easier to locate AfC submissions and review them for issues. Initially, the RfC called for the elimination of userspace drafts, but the RfC was changed early on to continue allowing userspace drafts. Before the creation of draftspace, drafts were stored in userspace (as many still are today), or subpages of Wikipedia:Article Incubator or Wikipedia:Articles for creation. Today, draftspace is used for AfC as well as for incubating articles that were created in mainspace but weren't quite ready for primetime (for example, because they didn't have enough references to meet the general notability guideline).
The "Rethinking draft space" discussion currently going on the village pump does not contain any specific policy proposals, but rather seeks to start a discussion on whether the draft namespace should be reformed or eliminated. The section was created by TonyBallioni after he came "to the conclusion that draft space is a failure, and for the most part is something that is used as a holding ground for G13 since the majority of the content is unsalvageable." As such, he supports eliminating draftspace and returning AfC to a model of userspace submissions. Opponents of draftspace argue that drafts are less likely to be seen and improved by editors, and so they just end up getting deleted after they are abandoned by their creators. Other users support keeping draftspace because it reduces the burden placed on new page patrollers (who are already severely backlogged), and keeps poorly written content and content from editors with a conflict of interest out of mainspace, where they would be visible to more readers.
In brief
- On the policy village pump: should geonotices be allowed to contain political advocacy? This RfC was caused by the addition of a geonotice saying, "Please send email asking the US government to require open access to federally supported research." A wide majority of users have opposed using geonotices for any political advocacy (though some suggested an exception for issues that directly affect Wikipedia, such as SOPA); others saw the geonotice as in line with the Wikimedia movement's goals. There were also complaints that this controversial geonotice had not been put up for discussion in a more frequently visited page like the village pump (in fact, the author of this column didn't even know the geonotice request board existed until he wrote this paragraph).
- On the reliable sources noticeboard, there is an ongoing discussion on how to improve the process of deprecating and blacklisting consistently unreliable sources. The proposals concern text to be added to WP:RSPI, WT:SBL, and WP:RSN explaining the requirements for a source to be deprecated or blacklisted.
- On Wikipedia talk:Manual of Style/Biography: the section of the Manual of Style on the capitalization of job titles (such as President of the United States) has been controversial for a long time and led to many edit wars. Opponents of MOS:JOBTITLES argue that it is confusing and does not have the support of the community, while supporters point towards its consistency with the style guides of reputable English-language sources.
Unfinished business
Jytdog
Wikipedia:Arbitration/Requests/Case/Jytdog was reopened on March 9, 2020. Until now, the original 2018 case request was in an unusual state of limbo: it was accepted, but the case will not be opened at this time in light of Jytdog's statement that he is retiring from Wikipedia...
on December 9, 2018.
A unanimous decision to reopen the case was reached by Arbcom on March 5 after receiving a communication from Jytdog expressing the wish to return to the community. Committee member Bradv gave the account Jytdog2 the confirmed user permission in order to initiate an Arbcom case.
The case is in its workshop phase as of our writing deadline.
Anti-harassment RfC
An anti-harassment Request for Comment (RfC) under the aegis of the Arbitration Committee was mentioned as a follow-on action during the Fram case last year (see the September 30, 2019 Special report for details). The draft RfC was posted on March 16, and was not yet open for comments as of our writing deadline.
Motorsports
Motorsports case was accepted February 28 as a content issue we cannot resolve
, according to Arbitrator David Fuchs. A proposed decision was due March 27 – as of our writing deadline, it has not been posted.
"I have been asked by Jeffrey Epstein …"

The life of reputed billionaire[1] Jeffrey Epstein took many strange turns. So did the articles about him on Wikipedia. In 2008, he was convicted of soliciting a minor for prostitution, served 13 months in a Florida jail, and was required to register as a sex offender. He allegedly committed illicit sexual activities while he was on work release from jail,[2] and was suspected of continuing them through at least 2015.[3]
Ultimately, he was accused of additional serious offenses, including sex trafficking, resulting in his July 2019 arrest. That month, publicity about the lenient plea deal in Epstein's 2008 case resulted in the resignation of US Secretary of Labor, Alexander Acosta, who as U.S. attorney for Southern Florida had approved the deal.[4] Epstein died in jail in August 2019, his death ruled a suicide by the New York City medical examiner.[5]
Between his 2009 release from jail and his second arrest, the editing got interesting on Wikipedia. Epstein began an extensive campaign to whitewash his reputation. Most notably, he claimed large donations to well-known academics through his charitable foundations.[6] Given his heinous crimes, the probable high-level political interest in the story, and the campaign to whitewash his reputation, in retrospect Wikipedia's article on Epstein seems like an obvious potential target for conflict-of-interest or paid editing.
The New York Times on November 26, 2019, broke a story about Wikipedia editing by accounts with probable links to Epstein. The Times wrote that after his 2008 conviction, Epstein named reputation management services that he used, and a Wikipedia user account, "Turville", appeared in information Epstein provided.[6] However there is no User:Turville registered on Wikipedia, and the Times suggested that User:Turvill (without an "e"), was the account referred to.
This Signpost report investigates whether User:Turvill and other accounts were associated with Epstein and how their edits affected two articles on Epstein. It is important to note that no purely on-Wiki investigation can prove the identity of a user account. For example other people may impersonate an editor in order to embarrass them, a tactic known as Joe jobbing. We cannot conclusively determine whether Epstein himself, employees of the Jeffrey Epstein VI Foundation, reputation management companies, or other types of paid editors edited the Wikipedia articles about Epstein. We can however gather evidence about how editors who associated themselves in some way with Epstein affected the articles.
The Epstein article
The Wikipedia article on Epstein was created on August 4, 2006, a week after Epstein's first indictment and two years before his conviction. Within hours a reliable source was added, citing CNN on the indictment.
Over the next two years the article grew to include 15 references, almost all of them about the sex scandal or investigation, until on June 30, 2008, when Epstein pleaded guilty and the plea was noted in Wikipedia.
However, not all was well with the article during this time. A lot of material, mostly unreferenced and complimentary to Epstein was added to the top of the article and all the referenced material on the criminal case was pushed to the bottom. From October 2007 to February 2008 one IP editor made six major deletions of material on the sexual allegations and related lawsuits.
In December 2011 there was more conflict among editors. Wikipedia editors had been keeping the article up to date, with reliable sources—until the arrival of editors favoring Epstein. Trouble began when User:Stgeorge12 reverted an administrator and removed material about the sexual offense conviction with the edit summary "I have been asked by Jeffrey Epstein to describe his biography in a professional and accurate way, that does not involve any scandals or disreputable content. As a living person, this is his right." On January 7, 2012, Stgeorge12 was indefinitely blocked for this and similar edits, at exactly the same time as another new editor, User:Ottotiv, who had made similar edits. These single-purpose accounts had established a pattern of obstruction and interference that would continue with User:Turvill.
Turvill

Six weeks after Stgeorge12 was indefinitely blocked, User:Turvill made their first edits, with five of the first seven edits on talk pages discussing deleting the Jeffrey Epstein article or protesting the proposed deletion of Jeffrey Epstein (plastic surgeon), which they called "my article".
Turvill has associated themself with Epstein by uploading flattering photos of Epstein to Wikimedia Commons with one described "Previously published: on my website, on facebook www.jeffreyepstein.org". When these files were deleted from Commons because the copyright permission was poorly formatted, Turvill implied that Epstein's foundation would release the photos. Turvill also tried to get a public domain Florida mugshot of Epstein speedily deleted from Commons because it was a "personal attack; violation of biography of a living person."
Turvill's main topic for editing was an article they helped create on the Jeffrey Epstein VI Foundation. Using the articles for creation procedure, an IP editor proposed the article on March 24, 2013, but Turvill took control of it two days later and made the vast majority of edits on it until August 20, 2013, when it was accepted as an article.
The article as first accepted claimed that the foundation funded projects worth "$200 million a year." The New York Times[6] published financial statements from the foundation showing that, in total over 18 years, the foundation funded less than $20 million in projects.[7] The article as first accepted also included a 100 word biography of Epstein which did not mention his conviction for soliciting a minor for prostitution.

Turvill was a single-purpose account devoted to articles related to Epstein. Turvill occasionally signed an edit in text as "Turville" (with an "e") or once as "Tuville" resulting in their IP address being posted on talk pages. The IP editor posted 25 of their 31 edits on the same pages where Turvill contributed. Turvill's last edit on Wikipedia was in January 2015 when they removed the words "convicted paedophile" from the foundation article.
In March 2012 and again in July 2012, Turvill was warned about editing warring on the Jeffrey Epstein article. Following the November 26 New York Times article, Carrite asked Turvill whether they would make a paid editing declaration, even though Turvill had not edited in almost five years. The next day Turvill was indefinitely blocked for "(Spam / advertising-only account WP:UPE)", where "UPE" refers to "undeclared paid editing".

Connections with MIT Media Lab
In the same month that Turvill began editing the Jeffrey Epstein VI Foundation article, Epstein met the director of the Massachusetts Institute of Technology's Media Lab, Joi Ito for the first time, with both interested in a donation to the Media Lab. On March 2, 2013, Ito requested staff members to conduct due diligence on Epstein.[8] One of them responded by email two days later:
| “ | You should read his Wikipedia bio, there may be some other things to consider. Though he seems to be a generous philanthropist, he might not be an individual the Lab should work with.
http://en.wikipedia.orgview_html.php?sq=Qlik&lang=&q=Jeffrey_Epstein[8] |
” |
In an independent report commissioned by MIT, the authors noted six sentences or paragraphs in the Wikipedia article that could have warned Ito that MIT should not accept Epstein's money, although the article "also included statements that could be read as undercutting the strength of some of the allegations."[8]
The MIT report noted that MIT did consider the possible risks to MIT's reputation when they accepted Epstein's money, but MIT "did not appropriately take into account the significant damage to the MIT community, particularly victims of sexual assault and abuse, from allowing Epstein to associate himself with MIT."[8]
Some staffers at the Media Lab were clearly worried about Epstein's victims. Epstein visited the MIT Media Lab in 2016, about a year after Turvill's final edit. According to an MIT staffer interviewed by Ronan Farrow in The New Yorker,[3] two young women accompanied Epstein on the visit. "They were models. Eastern European, definitely … All of us women made it a point to be super nice to them. We literally had a conversation about how, on the off chance that they're not there by choice, we could maybe help them."
Conclusion
Wikipedians reported on the Epstein investigation soon after it was announced in 2006, and they reported his conviction and many details of other allegations against him. But they were regularly opposed by single-purpose editors who removed material on Epstein's conviction or otherwise whitewashed the articles. Two of these editors associated themselves with Epstein or his foundation.
These Epstein-related accounts were not enough to prevent the Wikipedia article on Epstein from alerting MIT to Epstein's offenses, but they did soft-pedal the story enough that MIT managed to ignore the alert long enough to accept Epstein's money. Wikipedia's editors performed their work well in a difficult situation.
References
- ^ Voytko, Lisette (16 July 2019). "Court Documents Confirm Jeffrey Epstein Is Nowhere Near A Billionaire". Forbes. Retrieved 21 March 2020.
- ^ Baker, Mike (17 July 2019). "Sheriff to Investigate Jeffrey Epstein 'Work Release' After Allegation of Nude Meeting". The New York Times. Retrieved 21 March 2020.
- ^ a b Farrow, Ronan (7 September 2019). "How an Élite University Research Center Concealed Its Relationship with Jeffrey Epstein". The New Yorker. Retrieved 21 March 2020.
- ^ Helmore, Edward (12 July 2019). "Alex Acosta resigns as US labor secretary following Epstein plea deal scandal". Guardian. Retrieved 21 March 2020.
- ^ Barrett, Devlin (14 August 2019). "Jeffrey Epstein's autopsy concludes his death was a suicide by hanging". Washington Post. Retrieved 20 March 2020.
- ^ a b c Eder, Steven; Goldstein, Matthew (26 November 2019). "Jeffrey Epstein's Charity: An Image Boost Built on Deception". The New York Times. Archived from the original on 9 December 2019. Retrieved 21 March 2020.
- ^ "J. Epstein Virgin Islands Foundation , Inc" (PDF). The New York Times. Retrieved 21 March 2020.
- ^ a b c d Braceras, Roberto M.; Chunias, Jennifer L.; Martin, Kevin P. (10 March 2020). "Report Concerning Jeffrey Epstein's Interactions with the Massachusetts Institute of Technology" (PDF). Archived from the original (PDF) on 10 January 2020. Retrieved 22 March 2020.
Wikimedia community responds to COVID-19
This report outlines the "who" of Wikipedia's COVID-19 response – both individual editors and groups like Wikipedia:WikiProject COVID-19. We can not recognize every single one of the many, many contributors in this report or in our Wikiproject report interviews prepared for the issue. Everyone involved should take pride in their real-world impact which we have attempted to bring to light in this issue.
Projects
Many projects mobilized to encounter the COVID challenge.
A "WikiProject" is a group of people who collaborate in the Wikimedia platform to achieve some common goal in wiki content development or administration. Prior to COVID-19 various WikiProject communities were already in place engaged in their routine activities, but also had social and technical infrastructure in place to respond to a disease outreach or any other disaster.
WikiProject COVID-19 was created on March 15. For a deeper look into the community mobilization, see this issue's Community view.
WikiProject Medicine is visible in Wikipedia's COVID-19 response for coordinating the development of medical content, orienting new editors to contribute to Wikipedia, and mediating quality control. Within the Wikipedia community the project is the mainstay for developing health information on Wikipedia including 10,000+ articles on medical conditions, drugs, therapies, and certain events like outbreaks and humanitarian crises. Besides developing health content this WikiProject has a reputation for protection of Wikipedia content quality, recruiting off-wiki institutional collaboration, and joining discussion on all sorts of Wikipedia policy.

Illustrated in the accompanying graphic, WikiProject Medicine experienced extraordinary and unprecedented effects starting in early March:
- Rarely does the most edited article in medicine get more than 400 edits in a week
- This bar has never been all red before, so current editing is beyond the intended scale
- This is the first time that all top 10 articles in medicine were about one topic
Other content-focused WikiProjects which contribute to the effort include WikiProject Disaster management, WikiProject Viruses, and WikiProjects for every region in the world with special mention to WikiProjects Italy and China. The newly created WikiProject COVID-19 serves as a central forum for coordinating planning among these various projects. Beyond English Wikipedia and into other Wikimedia projects, Wikidata presents WikiProject Humanitarian Wikidata, which coordinates data collection for disease outbreaks and varied other disasters including climate change effects, violent attacks, and plane crashes. Newly created is Wikidata's own data-oriented WikiProject COVID-19, a WikiProject modeled after the previous comparable disease outbreak which the wiki community documented in WikiProject Zika Corpus in the Wikicite model of academic journal curation.
A cross-wiki administrative WikiProject which suddenly is very useful is WikiProject remote event participation, which gives guidance to wiki contributors on how they can meet each other online to discuss and develop Wikimedia content using shared document editing, voice and video chat, and of course conventional collaborative editing of the wiki.
Extraordinary contributors in extraordinary times
Many, many other editors have contributed and we can not recognize every single one of them. According to research done for The Signpost, the following contributors stood out in their especially prolific contributions to the articles and other organization (such as navigation boxes).
In-person events canceled
COVID-19 has been the cause of many event cancellations. Wiki community organizers have similarly had to cancel their events. In addition, many community events were cancelled due to public health concerns; these are also detailed in this issue's Special report.
Volunteer organizers host wiki community events continually around the world. The most common event type are the local events which a regional Wikimedia community organization presents to nearby wiki editors and the general public. There is a global tradition of organizing events in the Art+Feminism program every March, and this year there were cancellations for most of the 300 scheduled in-person events which in previous years had 4000+ attendees editing Wikipedia articles about female artists and their artwork.
The Wikimedia Summit is an annual gathering of representatives of each Wikimedia community organization around the world; its objective is global coordination to address the most urgent challenges of the Wikimedia Movement's strategic planning. The April 2020 Wikimedia Summit was planned to review the long-term planning discussions of the past 4 years to present governance recommendations through the year 2030 to the Wikimedia Foundation Board of Trustees. This event is cancelled.
Wikimedia ally Creative Commons has developed the free and open copyright license which Wikimedia projects use. Their annual summit in May in Portugal is cancelled. The Wikimedia Hackathon 2020 to develop MediaWiki, our shared software platform, is cancelled and will not happen in May 2020 in Tirana, Albania as scheduled. Wikimedia LGBT+ was planning its first international gathering to put LGBT+ wiki editors from as many countries as possible together face to face in Linz, Austria in May 2020, but that conference is cancelled. The WikiData Days 2020 2–4 July, Lisbon, Portugal is cancelled. The largest wiki conference, Wikimania 2020 in August in Bangkok, is pending a decision which the organizers will issue by the beginning of April 2020. 1,500 attendees would be expected at this conference which was planned especially to support contributors from South Asia and Southeast Asia.
Disease outbreak uncertainties, AfD forecasting, auto-updating Wikipedia
A monthly overview of recent academic research about Wikipedia and other Wikimedia projects, also published as the Wikimedia Research Newsletter.
See also the page of the monthly Wikimedia Research Showcase for videos and slides of past presentations.
"Uncertainty During New Disease Outbreaks in Wikipedia"
From the abstract and the discussion section:[1]
"New disease outbreaks [e.g. Ebola, MERS, Swine influenza] are often characterized by emergent and changing information which, in turn, require Wikipedia editors to spend time and effort to retrieve and understand information that is sometimes ambiguous, complex, and contradictory. [...] the goals of this study are to identify types of uncertainty expressed by Wikipedia editors during new disease outbreaks, and examine different strategies deployed by Wikipedia editors to manage uncertainty. [...]
Wikipedia editors depend on several strategies to cope with uncertainty during a disease outbreak. These strategies rely primarily on consulting authoritative sources, reporting the uncertainty to the public, ignoring the uncertainty in the interests of maintaining simplicity, and, to a far lesser extent, setting up a mailing list to gather information and science as they emerge over time."
"Analyzing Wikipedia Deletion Debates with a Group Decision-Making Forecast Model"
From the abstract:[2]
"we show that machine learning with natural language processing can accurately forecast the outcomes of group decision-making in online discussions. Specifically, we study Articles for Deletion, a Wikipedia forum for determining which content should be included on the site. Applying this model, we replicate several findings from prior work on the factors that predict debate outcomes; we then extend this prior work and present new avenues for study, particularly in the use of policy citation during discussion. Alongside these findings, we introduce a structured corpus and source code for analyzing over 400,000 deletion debates spanning Wikipedia's history."
"Science Is Shaped by Wikipedia: Evidence From a Randomized Control Trial"
From the abstract and discussion section:[3]
"Incorporating ideas into Wikipedia leads to those ideas being used more in the scientific literature. We provide correlational evidence of this across thousands of Wikipedia articles and causal evidence of it through a randomized control trial where we add new scientific content to Wikipedia. In the months after uploading it, an average new Wikipedia article in Chemistry is read tens of thousands of times and causes changes to hundreds of related scientific journal articles. Patterns in these changes suggest that Wikipedia articles are used as review articles, summarizing an area of science and highlighting the research contributions to it. Consistent with this reference article view, we find causal evidence that when scientific articles are added as references to Wikipedia, those articles accrue more academic citations. [...]
For each Wikipedia article that we created for this experiment we paid students $100. Assuming one Wikipedia article (or equivalent contribution) per research paper, the implicit tax on research would be ($100/$220,000 ) = 0.05%. [...] even with many conservative assumptions, dissemination through Wikipedia is ∼ 120× more cost-effective than traditional dissemination techniques."
This research caused community discussions that ultimately led to the creation of a "Wikipedia is not a laboratory" policy on the English Wikipedia.
"'This is exactly how the Nazis ran it': (De)legitimising the EU on Wikipedia"
From the abstract:[4]
"The data examined consist of Wikipedia contributors' debates that took place on a Wikipedia discussion site ('talk page'). Taking a corpus-assisted approach combined with argumentation analysis and aspects of systemic functional linguistics, I found that Wikipedia editors repeatedly propose that Nazi Germany might have been a precursor of the EU today. However, the Wikipedia community ultimately rejects this notion and emphasises the voluntary nature guiding the EU's creation process. Thus, while the EU's legitimacy is indeed contested in the course of the debates, the Wikipedia community eventually rejects this challenge."
"The Dynamics of Peer-Produced Political Information During the 2016 U.S. Presidential Campaign"
From the abstract:[5]
"Drawing on systems justification theory and methods for measuring the enthusiasm gap among voters, this paper quantitatively analyzes the candidates’ biographical and related articles and their editors. Information production and consumption patterns match major events over the course of the campaign, but Trump-related articles show consistently higher levels of engagement than Clinton-related articles."
"Wikipedia2Vec: An Efficient Toolkit for Learning and Visualizing the Embeddings of Words and Entities from Wikipedia"
From the tool documentation and abstract:[6]
Wikipedia2Vec is a tool for learning embeddings of words and entities from Wikipedia. The learned embeddings map similar words and entities close to one another in a continuous vector space.
This tool learns embeddings of words and entities by iterating over entire Wikipedia pages and jointly optimizing the following three submodels:
- Wikipedia link graph model, which learns entity embeddings by predicting neighboring entities in Wikipedia's link graph [...]
- Word-based skip-gram model, which learns word embeddings by predicting neighboring words given each word in a text contained on a Wikipedia page.
- Anchor context model, which aims to place similar words and entities near one another in the vector space[ ...]
The embeddings of entities in a large knowledge base (e.g., Wikipedia) are highly beneficial for solving various natural language tasks that involve real world knowledge. In this paper, we present Wikipedia2Vec, a Python-based open-source tool for learning the embeddings of words and entities from Wikipedia. [...] We also introduce a web-based demonstration of our tool that allows users to visualize and explore the learned embeddings."
"Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs"
From the abstract:[7]
" ...we provide an overview over [...] recent advancements [in question answering research], focusing on neural network based question answering systems over knowledge graphs [including "the most popular KGQA datasets": 8 based on Freebase, 2 on DBPedia, one on DBpedia and Wikidata]. We introduce readers to the challenges in the tasks, current paradigms of approaches, discuss notable advancements, and outline the emerging trends in the field."
"Automatic Fact-guided Sentence Modification"
From the abstract:[8]
"Online encyclopediae like Wikipedia contain large amounts of text that need frequent corrections and updates. The new information may contradict existing content [....] we focus on rewriting such dynamically changing articles. [...] To this end, we propose a two-step solution: (1) We identify and remove the contradicting components in a target text for a given claim, using a neutralizing stance model; (2) We expand the remaining text to be consistent with the given claim, using a novel two-encoder sequence-to-sequence model with copy attention. Applied to a Wikipedia fact update dataset, our method successfully generates updated sentences for new claims... "
See also university press release: "Automated system can rewrite outdated sentences in Wikipedia articles" ("Text-generating tool pinpoints and replaces specific information in sentences while retaining humanlike grammar and style") and media coverage.
"Transforming Wikipedia into Augmented Data for Query-Focused Summarization"
This preprint[9] presents a query-focused summarization dataset using Wikipedia's citations to align queries and documents.
"Knowledge Graphs and Knowledge Networks: The Story in Brief"
This summary of the journey of knowledge graphs for Artificial Intelligence[10] also covers Wikidata:
"Wikidata (wikidata.org/) is wikipedia’s open-source machine-readable database with millions of entities where everyone can contribute and use (with reading and editing permissions) with a user-friendly query interface.
It covers a wide variety of domains and contains not only textual knowledge but also images, geocoordinates, and numerics. Wikidata uses unique identifiers for each entity/ relation for accurate querying and provides provenance metadata, unlike DBpedia and schema.org. For instance, it includes information about a fact’s correctness in terms of its origin and temporal validity (reference point of time during of the fact). Wikidata is one of the latest projects acknowledging the dynamic nature of KG and is continuously updated by human contributors unlike DBpedia which is curated from wikipedia once in a while."
"Strangers in a seemingly open-to-all website: the gender bias in Wikipedia"
From the abstract:[11]
"Based on action research with a mixed evaluation method and two rounds of interviews, the research followed the steps of 27 Israeli women activists who participated in editing workshops.
Findings: [...] having the will to edit and the knowledge of how to edit are necessary but insufficient conditions for women to participate in Wikipedia. The finding reveals two categories: pre-editing barriers of negative reputation, lack of recognition, anonymity and fear of being erased; and post-editing barriers of experiences of rejection, alienation, lack of time and profit and ownership of knowledge. The research suggests a “Vicious Circle” model, displaying how the five layers of negative reputation, anonymity, fear, alienation and rejection enhance each other, in a manner that deters women from contributing to the website."
References
- ^ Tamime, Reham Al; Hall, Wendy; Giordano, Richard (2019-07-06). "Uncertainty During New Disease Outbreaks in Wikipedia". Proceedings of the International AAAI Conference on Web and Social Media. 13 (1): 38–46. ISSN 2334-0770.
- ^ Mayfield, Elijah; Black, Alan W. (November 2019). "Analyzing Wikipedia Deletion Debates with a Group Decision-Making Forecast Model". Proc. ACM Hum.-Comput. Interact. 3 (CSCW): 206–1–206:26. doi:10.1145/3359308. ISSN 2573-0142. Author's copy
- ^ Thompson, Neil; Hanley, Douglas (2019-08-16). "Science Is Shaped by Wikipedia: Evidence From a Randomized Control Trial". MIT Sloan Research Paper. doi:10.2139/ssrn.3039505.
- ^
Kopf, Susanne (2020-02-07). "'This is exactly how the Nazis ran it': (De)legitimising the EU on Wikipedia". Discourse & Society: 0957926520903524. doi:10.1177/0957926520903524. ISSN 0957-9265.

- ^ Keegan, Brian C. (November 2019). "The Dynamics of Peer-Produced Political Information During the 2016 U.S. Presidential Campaign". Proc. ACM Hum.-Comput. Interact. 3 (CSCW): 33–1–33:20. doi:10.1145/3359135. ISSN 2573-0142. Author's copy
- ^ Yamada, Ikuya; Asai, Akari; Sakuma, Jin; Shindo, Hiroyuki; Takeda, Hideaki; Takefuji, Yoshiyasu; Matsumoto, Yuji (2020-01-30). "Wikipedia2Vec: An Efficient Toolkit for Learning and Visualizing the Embeddings of Words and Entities from Wikipedia". arXiv:1812.06280 [cs.CL].
- ^ Chakraborty, Nilesh; Lukovnikov, Denis; Maheshwari, Gaurav; Trivedi, Priyansh; Lehmann, Jens; Fischer, Asja (2019-07-22). "Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs". arXiv:1907.09361 [cs.CL].
- ^ Shah, Darsh J.; Schuster, Tal; Barzilay, Regina (2019-12-02). "Automatic Fact-guided Sentence Modification". arXiv:1909.13838 [cs.CL].
- ^ Zhu, Haichao; Dong, Li; Wei, Furu; Qin, Bing; Liu, Ting (2019-11-08). "Transforming Wikipedia into Augmented Data for Query-Focused Summarization". arXiv:1911.03324 [cs.CL].
- ^ Sheth, Amit; Padhee, Swati; Gyrard, Amelie (July 2019). "Knowledge Graphs and Knowledge Networks: The Story in Brief". IEEE Internet Computing. 23 (4): 67–75. doi:10.1109/MIC.2019.2928449. ISSN 1941-0131.
- ^ Lir, Shlomit Aharoni (2019-01-01). "Strangers in a seemingly open-to-all website: the gender bias in Wikipedia". Equality, Diversity and Inclusion: An International Journal. ahead-of-print (ahead-of-print). doi:10.1108/EDI-10-2018-0198. ISSN 2040-7149. Copy at Academia.edu
Text from Wikipedia good enough for Oxford University Press to claim as own
- This op-ed was originally published on February 25, 2015.
- The views expressed in these op-eds are those of the authors only; responses and critical commentary are invited in the comments section. Editors wishing to submit their own op-ed should email the Signpost's editor.
| Ebola virus disease, 15:21, 25 December 2010 | Between 1976 and 1998, from 30,000 mammals, birds, reptiles, amphibians, and arthropods sampled from outbreak regions, no Ebolavirus was detected apart from some genetic material found in six rodents (Mus setulosus and Praomys) and one shrew (Sylvisorex ollula) collected from the Central African Republic.[1][2] The virus was detected in the carcasses of gorillas, chimpanzees, and duikers during outbreaks in 2001 and 2003, which later became the source of human infections. However, the high mortality from infection in these species makes them unlikely as a natural reservoir.[1]
Plants, arthropods, and birds have also been considered as possible reservoirs; however, bats are considered the most likely candidate.[3] Bats were known to reside in the cotton factory in which the index cases for the 1976 and 1979 outbreaks were employed, and they have also been implicated in Marburg infections in 1975 and 1980.[1] Of 24 plant species and 19 vertebrate species experimentally inoculated with Ebolavirus, only bats became infected.[4] The absence of clinical signs in these bats is characteristic of a reservoir species. In a 2002–2003 survey of 1,030 animals which included 679 bats from Gabon and the Republic of the Congo, 13 fruit bats were found to contain Ebolavirus RNA.[5] As of 2005, three fruit bat species (Hypsignathus monstrosus, Epomops franqueti, and Myonycteris torquata) have been identified as carrying the virus while remaining asymptomatic... Reston ebolavirus—unlike its African counterparts—is non-pathogenic in humans. The high mortality among monkeys and its recent emergence in swine, makes them unlikely natural reservoirs.[6] |
|---|---|
| Oxford Textbook of Zoonoses (2011). page 364 | ...Between 1976 and 1998, various mammals, birds, reptiles, amphibians, and arthropods from outbreak regions have been studied to determine the natural Fiolovirus reservoir. No Ebolavirus was detected apart from some genetic material found in six rodents (Mus setulosus and Praomys) and one shrew (sylvisorex ollula) collected from the Central African Republic (Peterson 2004). The virus was detected in the carcasses of gorillas, chimpanzees, and duikers during outbreaks in 2001 and 2003, which later became the source of human infections. However, the high mortality from infection in these species makes them unlikely as a natural reservoir.
Plants, arthropods, and birds have also been considered as possible reservoirs; however, bats are now considered the most likely candidate. Bats were known to reside in the cotton factory in which the Ebola index cases for the 1976 and 1979 outbreaks were employed. They have been implicated in the Marburg infections in 1975 and 1980. Of 24 plant species and 19 vertebrate species experimentally inoculated with Ebolavirus, only bats became infected (Swanepoel 1996). The absence of clinical signs in these bats is characteristic of a reservoir species. In a 2002-2003 survey of 1,030 animales, which included 679 bats from Gabon and the DRC, 13 fruit bats were found to contain Ebolavirus RNA (Pourrut 2009). As of 2005, three fruit bat species (Hypsignathus monstrosus, Epomops franqueti, and Myonycteris torquata) have been identified as carrying the virus while remaining asymptomatic... Reston ebolavirus—unlike its African counterparts—is non-pathogenic in humans. The high mortality among monkeys and its recent emergence in pigs makes them unlikely natural reservoirs. |
Last October, I came across the Oxford Textbook of Zoonoses (2011) published by Oxford University Press (OUP). I noticed that chapter 31, "Marburg and Ebola viruses", contained a fair bit of text that was nearly identical, word for word, as that in the Wikipedia article Ebola virus disease. A page from the book may be seen on Google Books, with at least the "natural reservoirs" section being nearly verbatim and some parts of the rest of the chapter containing great similarities.
Initially, I made an assumption that someone had copied and pasted from this book into Wikipedia. However, thankfully we have the ability to go back and view every version of Wikipedia that has ever existed. I could thus determine that the content in question was added to Wikipedia back in 2006 and was subsequently edited and expanded between then and 2010, when the greatest similarities occur. From this I could conclude that it was partly written by the Wikipedians ChyranandChloe and Rhys.
Next, I wondered whether one of these individuals was the author of the OUP chapter, namely, Graham Lloyd of the Special Pathogens Reference Unit at Porton Down. I contacted the user who had made the majority of the contributions, who turned out to be a virologist in Australia who assured me that while he had contributed to Wikipedia, he had never contributed to the Oxford Textbook of Zoonoses.
Finally, I looked for attribution of Wikipedia in the Oxford Textbook of Zoonoses and a release of this book under an open license as required by Wikipedia, and the result was that neither of these have been performed. The hardcover version of the Oxford Textbook of Zoonoses retails for $375. I discussed this issue with the legal team at the Wikimedia Foundation, who contacted the Oxford University Press. We were hoping that they could negotiate both attribution and release under an open license.
The reputation of Wikipedia in academia often seems to be that it is good enough for academics to use and even occasionally claim as their own work, but not good enough for either students or the “unwashed masses”. Thus I believed that convincing one of the world’s foremost medical publishers to both attribute and use an open license would be difficult. The legal team at the WMF, however, was optimistic. Initial emails from OUP indicated that this case would take longer than usual, as the people involved were “all over the world doing important Ebola work”. This, of course, is not the first time we have come across the academic literature copy and pasting from Wikipedia. In 2012, I discovered a medical textbook had also extensively copied from Wikipedia. (Also see the Signpost's 2012 special report on the misappropriation of Wikimedia content.)
At Wikipedia, we are happy to work with publishers. A year or so ago, I helped guide the company Boundless, which creates open access textbooks mostly based on Wikipedia content for first year university students, on how to appropriately attribute. These books were already released under a CC BY SA license. We attempted to work with the OUP in the same fashion.
On January 20, 2015, the OUP acknowledged that the content originated from Wikipedia and agreed to attribute Wikipedia, but were having difficulty with the open licensing. Following further inspection of the Oxford Textbook of Zoonoses , I found more inconsistencies. For example, while parts of the text were exactly the same, the author had not consistently used the same references. The references used on the Wikipedia article supported the text, but the references in the Oxford Textbook of Zoonoses that were changed did not support the text in question. The question remains as to why the references were changed. As a result of these changes, the quality of the copied content was lowered.
On February 5, 2015, I emailed the OUP offering to rewrite and update the chapter in question in collaboration with fellow Wikipedians. The next day, they replied via e-mail stating that they had already “independently decided to update the chapter and that that work [was] already in hand”. Writing a textbook chapter takes a fair length of time, likely weeks rather than a few days. Looking at the time line, it is questionable whether the OUP ever seriously intended to attribute Wikipedia. While our content passed their review processes, they claimed it was simply an “inadvertent omission of citation”. It is likely that a replacement chapter was requested immediately after the WMF legal department contacted OUP’s team.
The one good thing that has come out of all of this is that Wikipedia’s content passing a major textbook publisher review processes is some external validation of Wikipedia’s quality.
A look at the references
- Both Wikipedia and the Oxford Textbook of Zoonoses include "The absence of clinical signs in these bats is characteristic of a reservoir species. In a 2002–2003 survey of 1,030 animals which included 679 bats from Gabon and the Republic of the Congo, 13 fruit bats were found to contain Ebolavirus RNA". Wikipedia cites a 2005 article from Nature, which does support it. The Oxford Textbook of Zoonoses cites a 2009 article from BMC Infectious Diseases, which does not support it.
- Both include "no Ebolavirus was detected apart from some genetic material found in six rodents (Mus setulosus and Praomys) and one shrew (Sylvisorex ollula) collected from the Central African Republic". Wikipedia cites it to a 2005 article from Microbes and Infection which does support it, while the Oxford Textbook of Zoonoses cites [a 2004 article] from Emerging Infectious Diseases which does not support the content.
- Both state "Of 24 plant species and 19 vertebrate species experimentally inoculated with Ebolavirus, only bats became infected" and both use the same reference, a 1996 article from Emerging Infectious Diseases.
References
- ^ a b c Pourrut, X.; Kumulungui, B.; Wittmann, T.; Moussavou, G.; Délicat, A.; Yaba, P.; Nkoghe, D.; Gonzalez, J. P.; Leroy, E. M. (2005). "The natural history of Ebola virus in Africa". Microbes and infection / Institut Pasteur. 7 (7–8): 1005–1014. doi:10.1016/j.micinf.2005.04.006. PMID 16002313.
- ^ Morvan, J.; Deubel, V.; Gounon, P.; Nakouné, E.; Barrière, P.; Murri, S.; Perpète, O.; Selekon, B.; Coudrier, D.; Gautier-Hion, A.; Colyn, M.; Volehkov, V. (1999). "Identification of Ebola virus sequences present as RNA or DNA in organs of terrestrial small mammals of the Central African Republic". Microbes and Infection. 1 (14): 1193–1201. doi:10.1016/S1286-4579(99)00242-7. PMID 10580275.
- ^ "Fruit bats may carry Ebola virus". BBC News. 2005-12-11. Retrieved 2008-02-25.
- ^ Swanepoel, R. L.; Leman, P. A.; Burt, F. J.; Zachariades, N. A.; Braack, L. E.; Ksiazek, T. G.; Rollin, P. E.; Zaki, S. R.; Peters, C. J. (Oct 1996). "Experimental inoculation of plants and animals with Ebola virus". Emerging Infectious Diseases. 2 (4): 321–325. doi:10.3201/eid0204.960407. ISSN 1080-6040. PMC 2639914. PMID 8969248.
- ^ Leroy, E. M.; Kumulungui, B.; Pourrut, X.; Rouquet, P.; Hassanin, A.; Yaba, P.; Délicat, A.; Paweska, J. T.; Gonzalez, J. P.; Swanepoel, R. (2005). "Fruit bats as reservoirs of Ebola virus". Nature. 438 (7068): 575–576. Bibcode:2005Natur.438..575L. doi:10.1038/438575a. PMID 16319873.
- ^ Lubroth, Juan. "Ebola-Reston Virus in Pigs: Disease situation in swine in the Philippines". Food and Agriculture Organization of the United Nations. Retrieved 2009-09-27.
The only thing that matters in the world
- This traffic report is adapted from the Top 25 Report, prepared with commentary by Igordebraga (March 1 to 7); Serendipodous, Soulbust and Igordebraga (March 8 to 14); Rebestalic and Igordebraga (March 15 to 21); and Igordebraga (February 23 to 29).
This traffic report is brought to you by the letters "COVID", and the number 19. (Special thanks to both the WMF Tools and User:Jtmorgan for helping us compile the data while the regular tool is down)
Please note that news on COVID-19 has been rapidly developing. The descriptions of the historical articles given here may be out of date.
You Gotta Keep 'Em Separated (March 15 to 21)
.png)
| Rank | Article | Class | Views | Image | Notes/about |
|---|---|---|---|---|---|
| 1 | 2019–20 coronavirus pandemic | 7,645,103 |  |
Early 2020 bears the burden of a multinational pandemic caused by the Severe acute respiratory syndrome coronavirus 2. The page for the pandemic in particular is receiving so many views that WMFLabs' ever-useful Pageviews Anaylsis tool shows that all through this month there was never a day below 400k visitors... oh dear. | |
| 2 | Coronavirus | 2,749,576 |  |
The term 'Coronavirus' is a surprisingly broad one — it simply means any virus in a family which causes problems in mammals and birds. The Coronavirus family ranges from near-harmless common cold causers, to the one you see in the news — Severe acute respiratory syndrome coronavirus 2 — to the hulking (not literally), spree-slaying Middle East respiratory syndrome-related coronavirus, which, in its 2012 outbreak, presented victims with a ~35% chance of dying. The Coronaviruses are so named because of their peculiar spikes, called peplomers, which create an illusion of a stellar corona when viewed under an electron microscope. | |
| 3 | Spanish flu | 2,648,537 |  |
The Spanish flu was a flu pandemic that occurred from 1918 to 1920. One of the deadliest epidemics in recorded human history, the Spanish flu took place during a time when information was possibly being censored because of the war effort at the time. As for afterward, I don't know. All this censoring (which, by the way, was meant to keep morale up) left neutral country Spain as basically the only hard-hit country that took pains to accurately report infections – and so the pandemic was named after Spain (because countries thought Spain was the epicentre of the outbreak). | |
| 4 | Coronavirus disease 2019 | 2,455,634 |
|
The illness caused by the Severe acute respiratory syndrome coronavirus 2. | |
| 5 | 2020 coronavirus pandemic in Italy | 2,087,780 | |
Attention drawn by the Coronavirus pandemic is also concentrated on specific countries (as well as the general pandemic). Italy, considering deaths from infections, is the hardest-hit country in the world; doctors there have had to triage patients – who can be treated, who can't be. It's that hard. India's high standing here is probably due to its massive English-speaking population base. Same for the United States; in addition, the US currently has the very unfortunate position as the fastest-growing country in the world in terms of new infections. | |
| 6 | 2020 coronavirus pandemic in India | 1,923,144 | |||
| 7 | 2020 coronavirus pandemic in the United States | 1,752,639 | |||
| 8 | Kenny Rogers | 1,497,434 | 
|
Kenny Rogers is one of the best-selling musicians of all time, with a cool 100 million records sold during his lifetime; he was welcomed into the Country Music Hall of Fame in 2013. The Texan's 60-year career was punctuated with hits such as The Gambler and his cover of Islands in the Stream. Rogers passed away of natural causes at his home on the 20th of March this year. | |
| 9 | 2019–20 coronavirus pandemic by country and territory | 1,450,648 | 
|
Another Coronavirus article; this time, dealing with the actual impact of the pandemic. Take a look at the map to the left—red all around. It's not looking good... | |
| 10 | 2009 flu pandemic | 1,261,204 | 
|
This pandemic was caused by the same type of influenza that caused the Spanish Flu (H1N1; swine flu). Estimates of total infections from this pandemic range to 1.4 billion (see the infobox in that article). That's huge. |
You built walls to protect you, so no one will infect you (March 8 to 14)
.png)
| Rank | Article | Class | Views | Image | Notes/about |
|---|---|---|---|---|---|
| 1 | 2019–20 coronavirus outbreak / pandemic | 6,408,766 [a] | |
It seems the only thing that matters in the world is not getting infected with the strong, heavily contagious virus that since its outbreak in China last year has now reached pandemic status. All the movies that could've brought us to the theater were postponed, just about every sport (American and association football, basketball, hockey) stopped being played, and everywhere you see the words "social distancing" and "quarantine". | |
| 2 | Coronavirus | 2,883,888 | | ||
| 3 | Coronavirus disease 2019 | 1,762,421 | | ||
| 4 | Spanish flu | 1,582,872 | |
In the last 100 years, humanity has had to confront two great plagues: one was AIDS, the other was this monster, which struck a weakened world still broken by the horror of World War I, and was almost certainly speeded by it. The death toll is still debated today, and may have been as high as 100 million, though was more likely comparable to AIDS's 30 million. | |
| 5 | Pandemic | 1,517,718 |  |
The precise definition of this loaded word is vague, and even the World Health Organization is cautious in applying it. Even so, they declared the COVID-19 disease a pandemic this week. | |
| 6 | 2019–20 coronavirus outbreak / pandemic by country and territory | 1,480,438 [a] |  |
This epidemic is global, but its effects are local, and everyone will confront their own story, largely dependent on their country's response. | |
| 7 | 2009 flu pandemic | 1,272,019 |  |
This pandemic was essentially an encore for the 1918 flu. It was the same type, though a different strain, and infected about the same percentage of the world's population, but thankfully was far less virulent. Still many people were left with permanent damage to their lungs. | |
| 8 | 2020 coronavirus outbreak / pandemic in Italy | 1,262,160 [a] | .svg) |
Italy has been hit the worst of any country by this pandemic, with nearly 50,000 cases in a population of barely 60 million. Recently its death toll has crossed that of China, though some have suggested the data may be inflated. This may be due to Italy's greater percentage of elderly. | |
| 9 | 2020 coronavirus outbreak / pandemic in the United States | 1,164,003 [a] |  |
To translate how many people are feeling about the arrival and spread of the disease, let's borrow from Billy Joel by way of Patton Oswalt:
| |
| 10 | 2020 Democratic Party presidential primaries | 900,406 |  |
And now for something not related to diseases, but just as unhealthy (though more for the mind): politics! |
I've Got a Disease (March 1 to 7)
.png)
| Rank | Article | Class | Views | Image | About |
|---|---|---|---|---|---|
| 1 | 2019–20 coronavirus outbreak | 3.465.955 | |
The article is now 2019–20 coronavirus pandemic, showing how widespread the disease has gotten since it originated in China. | |
| 2 | 2020 Democratic Party presidential primaries | 2.331.572 |  |
The Republicans just went for a possible Trump re-election, so the Democrats instead are having a tight race, that after Super Tuesday (#4), has only three candidates left: #5, #7, and Tulsi Gabbard. | |
| 3 | Coronavirus | 2.106.989 |  |
The specific strain of this type of virus currently causing panic worldwide (#1) was known as 2019-nCoV and is now Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), but people just seek the general term. | |
| 4 | Super Tuesday | 1.356.307 | .jpg) |
11 states held their primaries (#2) on March 3, most of which were won by Joe Biden, Barack Obama's vice president who previously served as Senator for Delaware. | |
| 5 | Joe Biden | 1.086.375 | |||
| 6 | 2019–20 coronavirus outbreak by country and territory | 1.071.108 |  |
#1 started in China, and has gone onto over 100 countries (including the Vatican – see #10 as for why). The list also includes a cruise ship, the Diamond Princess, which had 696 cases (7 of them fatal) and is currently quarantined following an evacuation in the coast of Japan. | |
| 7 | Bernie Sanders | 985.977 | .jpg) |
After losing the Democratic presidential spot to Hillary Clinton in 2016, the Vermont Senator is currently trying again against #5. | |
| 8 | The Invisible Man (2020 film) | 964.377 | .jpg) |
Without the classic look seen to the left (that certainly would help avoid getting infected in times of our #1!) or previously attached star Johnny Depp, The Invisible Man was brought back in a cheaply made and highly effective thriller that got glowing reviews and already made over $100 million worldwide. | |
| 9 | Spanish flu | 773.875 |  |
Over a hundred years ago, another virus (the H1N1, which struck again in 2009) wiped out huge portions of the world population, and reportedly started in Europe – though not in Spain, that got the name because unlike other countries they didn't care if reporting on the deaths would be bad for morale. The current pandemic (#1) had its first major outbreak out of Asia in Italy, which is currently only behind disease source China. | |
| 10 | 2020 coronavirus outbreak in Italy | 754.327 | |
This could be The Last Time (February 23 to 29)
.png)
| Rank | Article | Class | Views | Image | About |
|---|---|---|---|---|---|
| 1 | 2019–20 coronavirus outbreak | 2.505.351 | |
While the disease has had most cases where it originated, Asia, it is now slowly spreading to other countries which received tourists from China. The global economy has been affected, and even James Bond is afraid of the virus. | |
| 2 | Tyson Fury | 2.420.792 |  |
This awesomely named boxer finally had a rematch for a 2018 fight that ended in a controversial split draw, and this time had a technical knockout on adversary Deontay Wilder (#6). | |
| 3 | Coronavirus | 1.954.483 | |
The specific strain of this type of virus currently causing panic worldwide (#1) was known as 2019-nCoV and is now Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), but people just seek the general term. But showing how things have gotten worse, now readers also want specifics on how and where the coronavirus is spreading. | |
| 4 | 2019–20 coronavirus outbreak by country and territory | 1.096.182 | |||
| 5 | Donald Trump | 1.064.391 | .jpg) |
The Tweeter-in-chief visited India (and its Prime Minister who he likes a lot), and the combination of an attention-hungry person with an information-seeking nation just had to bring him views on Wikipedia. | |
| 6 | Deontay Wilder | 1.018.424 |  |
The previously undefeated World Boxing Council heavyweight champion lost his belt to our #2 when the two boxers finally met again. | |
| 7 | The Invisible Man (2020 film) | 997.915 | .jpg) |
Once the idea of starting a cinematic universe with The Mummy failed miserably, Universal Studios gave up on making a related big budget Invisible Man starring Johnny Depp and instead gave the project to Leigh Whannell and Blumhouse Productions, who reworked the project to have Elisabeth Moss being stalked by her ex who found out a way to never be seen. It worked, with heaps of critical praise about how in spite of the low $7 million budget The Invisible Man is scarier and often better made than much more expensive thrillers, and it opened atop the box office. | |
| 8 | Bernie Sanders | 973.889 | |
After losing the Democratic presidential spot to Hillary Clinton in 2016, the Vermont Senator is currently leading the race for the 2020 run. | |
| 9 | Harvey Weinstein | 880.650 |  |
Justice is starting to be served to the film producer who harrassed, abused and even raped women in his heyday, as Weinstein was found guilty of two of five felonies in New York, which could send him to jail for up to 25 years. | |
| 10 | Super ShowDown (2020) | 824.654 |  |
WWE again went to Saudi Arabia, with the main card featuring "The Fiend" Bray Wyatt (pictured) losing to Bill Goldberg. |
Exclusions
- These lists exclude the Wikipedia main page, non-article pages (such as redlinks), and anomalous entries (such as DDoS attacks or likely automated views). Since mobile view data became available to the Report in October 2014, we exclude articles that have almost no mobile views (5–6% or less) or almost all mobile views (94–95% or more) because they are very likely to be automated views based on our experience and research of the issue. Please feel free to discuss any removal on the Top 25 Report talk page if you wish.
Visible Women on Wikipedia
Each year, Whose Knowlege? hosts the #VisibleWikiWomen project to increase the number of photographs of women, especially notable women and women from marginalized groups, on Wikimedia projects. It also includes photographs of women's artwork and other creations. The campaign brings together Wikimedia organizations (chapters and user groups) with feminist organizations, cultural institutions, community organizers and individuals from around the world to make women visible on Wikipedia and on the wider internet.
The third annual campaign started on March 8 and continues until May 8, 2020. These are some of the images from that campaign. To see more images from the project, visit the ![]() Media related to VisibleWikiWomen 2020 at Wikimedia Commons.
Media related to VisibleWikiWomen 2020 at Wikimedia Commons.

.jpg)
.jpg)
.jpg)


Señoritaleona who is the organizer of the #VisibleWikiWomen 2020 coordinator says:
| “ | We want to make sure all women are visible on Wikipedia and all Wikimedia projects, especially black, brown, indigenous, LGBTQIA and Global South women who are disproportionately affected by invisibility in our projects and across the web. That’s why, as part of this campaign, we make a targeted effort to increase the number of images that celebrate and affirm women from these marginalized groups. | ” |


_(cropped).jpg)
.jpg)

.jpg)


Penny Richards, who works with photos for the Women in Red project, says:
| “ | The women depicted in the images included in #VisibleWikiWomen are (or were) working, celebrating, aging human beings, with faces that might remind the viewer of a neighbor or a friend. Seeing these notable women reminds us that, in real life, achievement isn't always dressed up, nipped in, and perfectly-coiffed. It means that notable women laugh, scowl, squint, and rage. Our lives are saturated with images of women that are manipulated, airbrushed, and uncannily symmetrical; in compliant poses with perfect skin and eager smiles. I want to see real faces and shapes on Wikipedia. I want kids to see the whole amazing range of what interesting women look like. | ” |
.jpg)
.jpg)
.jpg)













.JPG)
.jpg)

















Suggested articles for editing:
- African-American women in computer science (needs expansion)
- Convict women in Australia (has issues and needs expansion)
- Gender pay gap in India (may include original research, needs verification)
- History of women in engineering (needs expansion)
- List of female librarians (very incomplete)
- List of women aviators (very incomplete)
- Women in Africa (could be expanded, has several redlinks)
- Women in Oceania (could be expanded, has several redlinks)
- Women's suffrage in Mexico (needs expansion)
Amid COVID-19, Wikimedia Foundation offers full pay for reduced hours, mobilizes all staff to work remote, and waives sick time
- Katherine Maher, the Wikimedia Foundation Chief Executive Officer and Executive Director, published this on March 6 and updated it March 14, 2020 at WMF News. Detailed updates are available on COVID-19 on Meta. -S
Update: On March 14, 2020, the Wikimedia Foundation announced new measures to support employees and protect general public health amid COVID-19. As part of these operational actions, we have:
- Closed both Foundation offices in San Francisco and Washington, DC, until at least March 31, 2020. All staff are now working remotely.
- Shifted to a reduced work week. Expectations are that staff may work 20 hours a week if necessary, and all will be paid according to their usual work schedules.
- Waived normal sick time requirements for staff who are ill or caring for others.
- Guaranteed all contract and hourly workers full compensation for planned hours worked.
- Cancelled all near-term, in-person gatherings until the World Health Organization declares the pandemic over.
Importantly, we have shifted our priorities to essential work, including keeping Wikipedia online and available for the world as a critical informational resource. Please see here for real-time updates about our COVID-19 response, as well as related resources.
The Wikimedia Foundation is closely monitoring developments with respect to the Coronavirus (COVID-19) and its potential impact on our staff and the communities in which we all live. Today, we’re sharing steps we’re taking to protect our employees and how we plan to do our part to prevent the spread of COVID-19.
For the remainder of March 2020, our San Francisco office will be closed to staff and visitors. We are putting in place measures to ensure that our San Francisco-based staff have resources and support to continue working remotely. Our Washington D.C. office will remain open for the time being, though we are encouraging everyone to take precautions to protect themselves and their communities and to work remotely where possible.
We have also temporarily suspended nonessential travel for all staff, and instituted a risk review process for any travel considered essential. In addition, we have been in touch with members of the Wikimedia movement community with respect to upcoming events and are taking necessary steps to cancel or postpone these, based on potential risks.
To ensure we continue to evaluate and take action to limit the spread of COVID-19, we have established a responding team of staff to monitor new developments and determine the appropriate measures as the situation further develops. This team will also be tasked with ensuring we have clear, actionable protocols and plans to maintain the continuity of technical needs to provide free knowledge for our hundreds of millions of users around the world.
Approximately 64 percent of Wikimedia Foundation staff are remote, and so we do not anticipate a major disruption in our work. That said, we’re continuing to evaluate and take necessary measures to meet the organization’s goals and priorities.
We encourage our staff, partners, volunteer communities, and everyone to take care of themselves during this time, and recognize the role each of us can play in not only limiting the spread of the disease for ourselves, but also for the communities we all live in. Stay safe, be well, and we’ll keep you updated as the situation develops.
What's making you happy this month?
The content of this Signpost piece is adapted from email threads titled "What's making you happy this week?" that are sent to Wikimedia-l.
We encourage you to add your comments about what's making you happy this month to the talk page of this Signpost piece.
Week of 1 March 2020: ¿Qué te está haciendo feliz esta semana?
From User:Pine

What's making you happy this week? is returning after an unplanned pause that was due to off-wiki events. User:Clovermoss and I agreed that we will try to alternate weeks writing this publication.
The Commons picture of the day for 1 March 2020 is of a hermitage, named Ermita del Santo Cristo de Miranda, which is located in Spain. I think that everyone should sometimes get a break for personal refreshment, such as by curling up in a chair with a book, going on a vacation or retreat, or pursuing a hobby.
A hobby that I enjoy is music. Here is a video clip from Star Trek: Voyager in which the ship's doctor and the character Seven of Nine sing a duet. This happens during a story line in which the Doctor gives Seven advice regarding romance. They sing an American English folk song, "You are my sunshine", which seems appropriate for this Signpost piece with the title "On the bright side": YouTube link.
-
 Seven of Nine was portrayed by actress Jeri Ryan
Seven of Nine was portrayed by actress Jeri Ryan -
 The Doctor was portrayed by actor Robert Picardo
The Doctor was portrayed by actor Robert Picardo -
 The Doctor's instruction to Seven of Nine regarding dating included dance lessons
The Doctor's instruction to Seven of Nine regarding dating included dance lessons -
 French-Canadian lumberjacks playing music while at camp
French-Canadian lumberjacks playing music while at camp




Week of 8 March 2020: Vad gläder dig den här veckan?
From User:Clovermoss

There is a lot that is making me happy this week. I'm happy that I'm back to contributing to "On The Bright Side" and the What's Making You Happy This Week? threads again because it's something I look forward to. It's nice to think and reflect upon the positivity across the Wikimedia movement.
This week, I read an interesting article from Wired entitled "Wikipedia Is The Last Best Place On The Internet". A link to the article can be found here: [1]. I really enjoyed reading this, and I agree that Wikipedia really has come a long way since 2007. The extent of Wikipedia's influence has grown considerably and has had such an impact on the world today that I really couldn't even imagine what the world would be like without it.
I am looking forward to the start of the Wikigap Challenge, which is taking place on March 8 through April 8, 2020. This challenge is receiving help from the UN Human Rights Office which is incredible and not something that happens everyday. However, it seems like there's always something interesting going on when I check Wikimedia-l, and that's thanks to the dedicated efforts of countless editors.
Week of 15 March 2020: Waar word jij blij van deze week?
From User:Pine
Preface
Mindful of the ongoing 2019–20 coronavirus pandemic, the tone of this week's email is more somber than some emails of the past. Let us hope that public health actions being taken in many places throughout the world are effective at "flattening the curve", so that health care systems are able to manage the peak number of people who are simultaneously in need of health services.
-
 World Health Organization representatives meet with Tehran city administrators
World Health Organization representatives meet with Tehran city administrators -
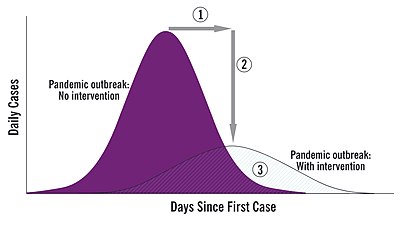 The goals of community mitigation: (1) delay outbreak peak; (2) decompress peak burden on healthcare, known as flattening the curve; and (3) diminish overall cases and health impact.
The goals of community mitigation: (1) delay outbreak peak; (2) decompress peak burden on healthcare, known as flattening the curve; and (3) diminish overall cases and health impact.

.jpg)
Project milestone
- Dutch Wikipedia has reached the 2,000,000 article milestone.
More good press for English Wikipedia from Wired
A couple of quotes from the latter article:
- "Heilman noted that Wikipedia has a structural advantage over the big social networks: 'It takes more time and effort to disrupt Wikipedia than it does to restore Wikipedia to a reliable level. It’s the exact opposite on Twitter and Facebook, where it takes a second to spread false news,' while getting those lies removed will take a lot of time and effort."
- "I spoke this week with the Wikipedia editor who guided the article about the new coronavirus from a one-sentence item in early January to a substantial article with charts of infections around the world. She goes by the handle Whispyhistory, and is a doctor in South London... The picture she paints of the project’s contributors is akin to the staff of a demanding teaching hospital."
Recognitions from the Affiliations Committee
- Myanmar Wikimedia Community User Group
- Wikigrannies User Group
- Wikimedia Community User Group CEE Spring
- Wikimedians for Sustainable Development
- Wikimedians of Turkic Languages User Group
- Wikimedians of United Arab Emirates User Group
Gallery
-
 Logo for Dutch Wikipedia's 2 million article milestone
Logo for Dutch Wikipedia's 2 million article milestone -
 Logo of the Myanmar Wikimedia Community User Group
Logo of the Myanmar Wikimedia Community User Group -
 Logo of the Wikigrannies User Group
Logo of the Wikigrannies User Group -
 Logo of Wikimedia Community User Group CEE Spring
Logo of Wikimedia Community User Group CEE Spring -
 Logo of the Wikimedians for Sustainable Development
Logo of the Wikimedians for Sustainable Development -
 Logo of the Wikimedians of Turkic Languages User Group
Logo of the Wikimedians of Turkic Languages User Group -
 Logo of the Wikimedians of United Arab Emirates User Group
Logo of the Wikimedians of United Arab Emirates User Group





Week of 22 March 2020: Cosa ti rende felice questa settimana?
From User:Clovermoss
There's been a lot that's made me happy this week. However, I realize that right now is a difficult time for a lot of people. Before I write about anything else, I would like to thank the real world heroes out there. I think that no words can accurately describe the cumulative effort and sacrifices that so many people are making everyday. I would especially like to thank doctors, nurses, and other medical professionals. I would like to thank people who provide shelter and food to other people in need. I want to thank the countless parents that are doing everything they can. I want to thank caregivers for what they do everyday. I extend my sympathies to anyone who is going through a really difficult time right now, because so many people are facing struggles that I can't even begin to imagine.
Sometimes, it's the small and seemingly inconsequential moments that can really matter. For me, that's been doing my best to do what I can. Living in those moments of joy where I find them. This week, that involved lots of oatmeal and tea, taking a brief walk outside to feel the wind, and reading for hours on end. I have also listened to music. If anyone is curious, I absolutely adore this song from The Sound of Music. I think I gravitated towards it because even though life can be scary sometimes, remembering your favourite things can help get you through that.
I've also spent time on Wikipedia, and there are a lot of good things happening on-wiki. There's a new WikiProject dedicated to Wikipedia's coverage of COVID-19 and the ongoing pandemic: WikiProject COVID-19. There are so many editors actively contributing there, and it's heartwarming to see this kind of intense collaboration and dedication. The ramifications of these actions have a very real impact on the real world. It's amazing that so many people are doing their best to help others. I'm thankful for that, and to everyone who tries to make the world a better place.
Gallery
-
 Oatmeal with blueberries
Oatmeal with blueberries -
 Stack of books
Stack of books -
 Logo for WikiProject COVID-19
Logo for WikiProject COVID-19


.svg)
Week of 29 March 2020: 这个星期让您感到开心的是什么?
From User:Pine
I would like to express gratitude to people who, instead of running away from the 2019–20 coronavirus pandemic, are "running toward the fire", especially people who voluntarily accept personal risks. This includes many health care workers and people who have other public service roles including civil protection volunteers, journalists, firefighters, security personnel, and people who provide other essential services such as in food banks, homeless shelters, nursery schools, public utilities, and transportation. I am thankful for their courage and sacrifices. Also, I am thankful for the many people who are sharing and publishing information for public benefit, including on Wikimedia projects, the Internet Archive, and OpenStreetMap.
Special thanks to User:Bdgzczy, who started the article on English Wikipedia regarding the pandemic; to User:Universehk who started the article on Chinese Wikipedia; and to Chinese doctors Ai Fen (艾芬) and Li Wenliang (李文亮), who gave other doctors early warnings about the virus.
- People helping people in the 2019–20 coronavirus pandemic
-
 A nurse measuring the body temperature of an outpatient in Hubei TCM Hospital, Wuhan, China
A nurse measuring the body temperature of an outpatient in Hubei TCM Hospital, Wuhan, China -
 A doctor wearing special protective suit for the Wuhan coronavirus outbreak treats a patient in Hubei TCM Hospital, Wuhan, China
A doctor wearing special protective suit for the Wuhan coronavirus outbreak treats a patient in Hubei TCM Hospital, Wuhan, China -
 A Protezione Civile (Civil Protection) volunteer measures the temperatures of people before they enter Guglielmo Marconi Airport in Italy
A Protezione Civile (Civil Protection) volunteer measures the temperatures of people before they enter Guglielmo Marconi Airport in Italy -
 New York National Guard soldiers hand groceries to members of the community at a food distribution point at Hope Community Services in New Rochelle, United States
New York National Guard soldiers hand groceries to members of the community at a food distribution point at Hope Community Services in New Rochelle, United States -
 A supply fence for the needy in Kiel during the COVID-19 pandemic in Schleswig-Holstein, Germany
A supply fence for the needy in Kiel during the COVID-19 pandemic in Schleswig-Holstein, Germany -
 A sign that says "Keep Calm and Edit" with the Wikipedia logo
A sign that says "Keep Calm and Edit" with the Wikipedia logo


.jpg)
.jpg)
-msu-1019.jpg)

From User:Clovermoss
Once again, I would like to express my sympathies. There are so many people going through so much right now. It's difficult to write words that can even begin to describe it all.
COVID-19 has impacted so many aspects of everyday life. Many people are relying on Wikipedia for reliable and accurate information, and the 2019–20 coronavirus pandemic article receives more than a million pageviews daily. As of the time of writing this, there are 597 articles within the scope of WikiProject COVID-19. There is an article about the outbreak in 110 languages, which collectively have received more than 34.9 million pageviews.[2] Editors from across the world are collaborating together to make Wikipedia a better place, and that is something I am incredibly thankful for.
I'm also thankful for all the people who are supporting others. The everyday heroes of our world: healthcare workers, parents, caregivers, volunteers, and countless others. Thank you for making the world a better place.
Regarding translations
Skillful translations of the sentence "What's making you happy this week?" would be very much appreciated. If you see any inaccuracies in the translations in this article then please {{ping}} User:Pine or User:Clovermoss in the discussion section of this page, or boldly make the correction to the text of the article. Thank you to everyone who has helped with translations so far.
Your turn
What's making you happy this month? You are welcome to write a comment on the talk page of this Signpost piece.